DrawMon: A Distributed System for Detection of Atypical Sketch Content in Concurrent Pictionary Games
Nikhil Bansal Kartik Gupta Kiruthika Kannan Sivani Pentapati Ravi Kiran Sarvadevabhatla
What is atypical sketch content and why do we need to detect them?
AtyPict- the first ever dataset of atypical whiteboard content
The categories of atypical content usually encountered in Pictionary sessions are:
- Text: Drawer directly writes the target word or hints related to the target word on the canvas.
- Numerical: Drawer writes numbers on canvas.
- Circles: Drawers often circle a portion of the canvas to emphasize relevant or important content.
- Iconic: Other items used for emphasizing content and abstract compositional structures include drawing a question mark, arrow and other miscellaneous structures (e.g. double-headed arrow, tick marks, addition symbol, cross) and striking out the sketch (which usually implies negation of thesketched item).
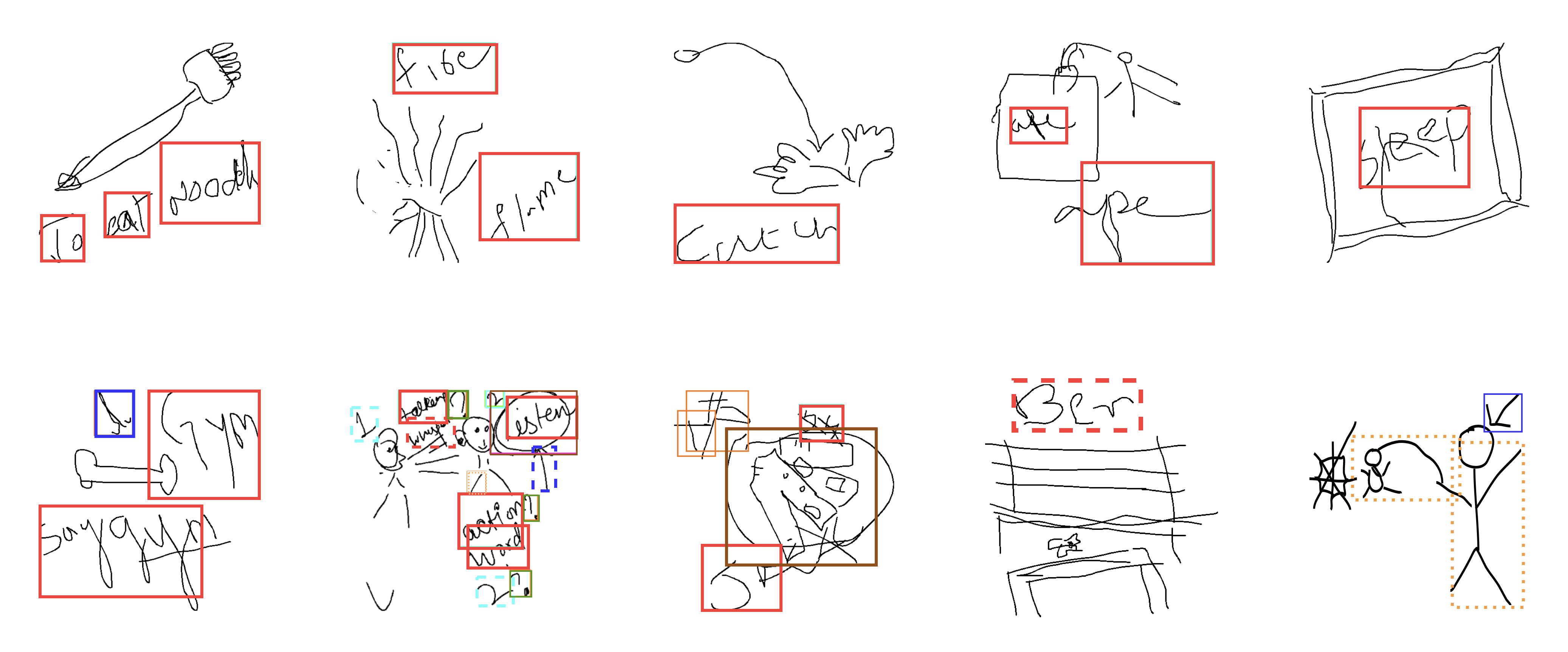
Examples of atypical content detection. False negatives are shown as dashed rectangles and false positives as dotted rectangles. Color codes are: text, numbers, question marks, arrows, circles and other icons (e.g. tick marks, addition symbol).
Screenshots of our data collection tool showing Drawer (left) and Guesser (right) activity during a Pictionary game. In this case, the Drawer has violated the game rules by writing text (`Spiderm') on the canvas. An automatic alert notifying the player (see top left of screenshot) and identifying the text location (red box on canvas) is generated by our system DrawMon.
CanvasDash: an intuitive dashboard UI for annotation and visualization
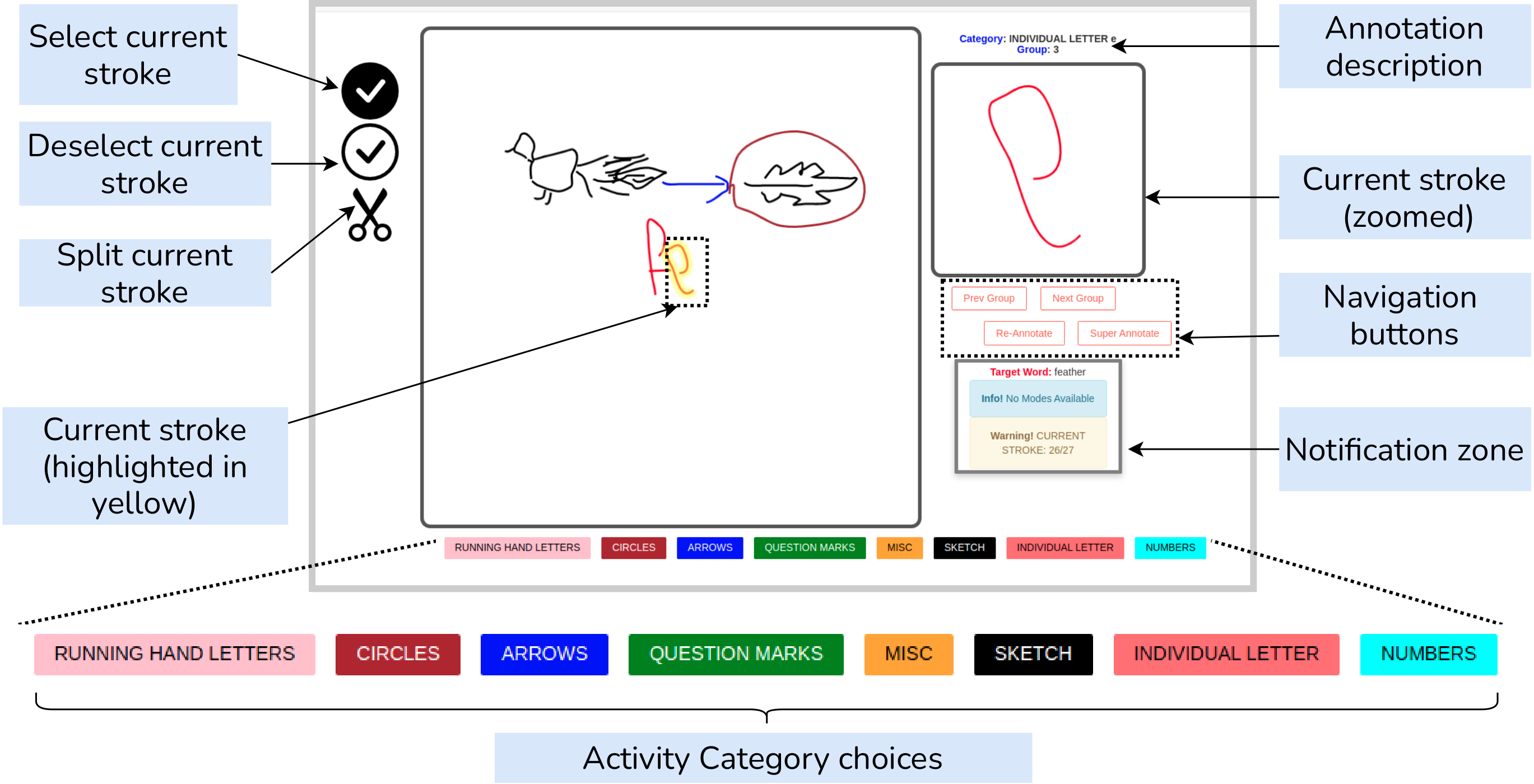
An illustration of annotation using our Canvas-Dash interface.
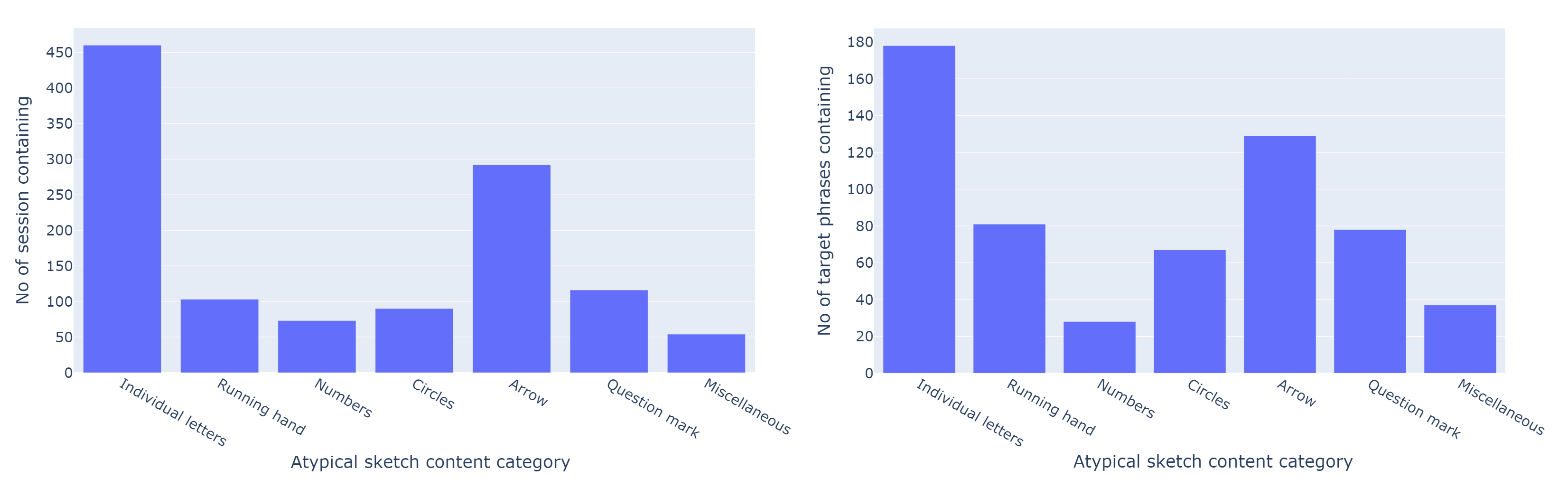
The distribution of atypical content categories show significant imbalance with category 'Individual letters' occurring more often than others.
DrawMon: a distributed system for sketchcontent-based alert generation
DrawMon - a distributed alert generation system (see figure below). Each game session is managed by a central Session Manager which assigns a unique session id.
- For a given session, whenever a sketch stroke is drawn, the accumulated canvas content (i.e. strokes rendered so far) is tagged with session id and relayed to a shared Session Canvas Queue.
- For efficiency, the canvas content is represented as a lightweight Scalable Vector Graphic (SVG) object. The contents of the Session Canvas Queue are dequeued and rendered into corresponding 512×512 binary images by Distributed Rendering Module in a distributed and parallel fashion.
- The rendered binary images tagged with session id are placed in the Rendered Image Queue. The contents of Rendered Image Queue are dequeued and processed by Distributed Detection Module. Each Detection module consists of our custom-designed deep neural network CanvasNet.
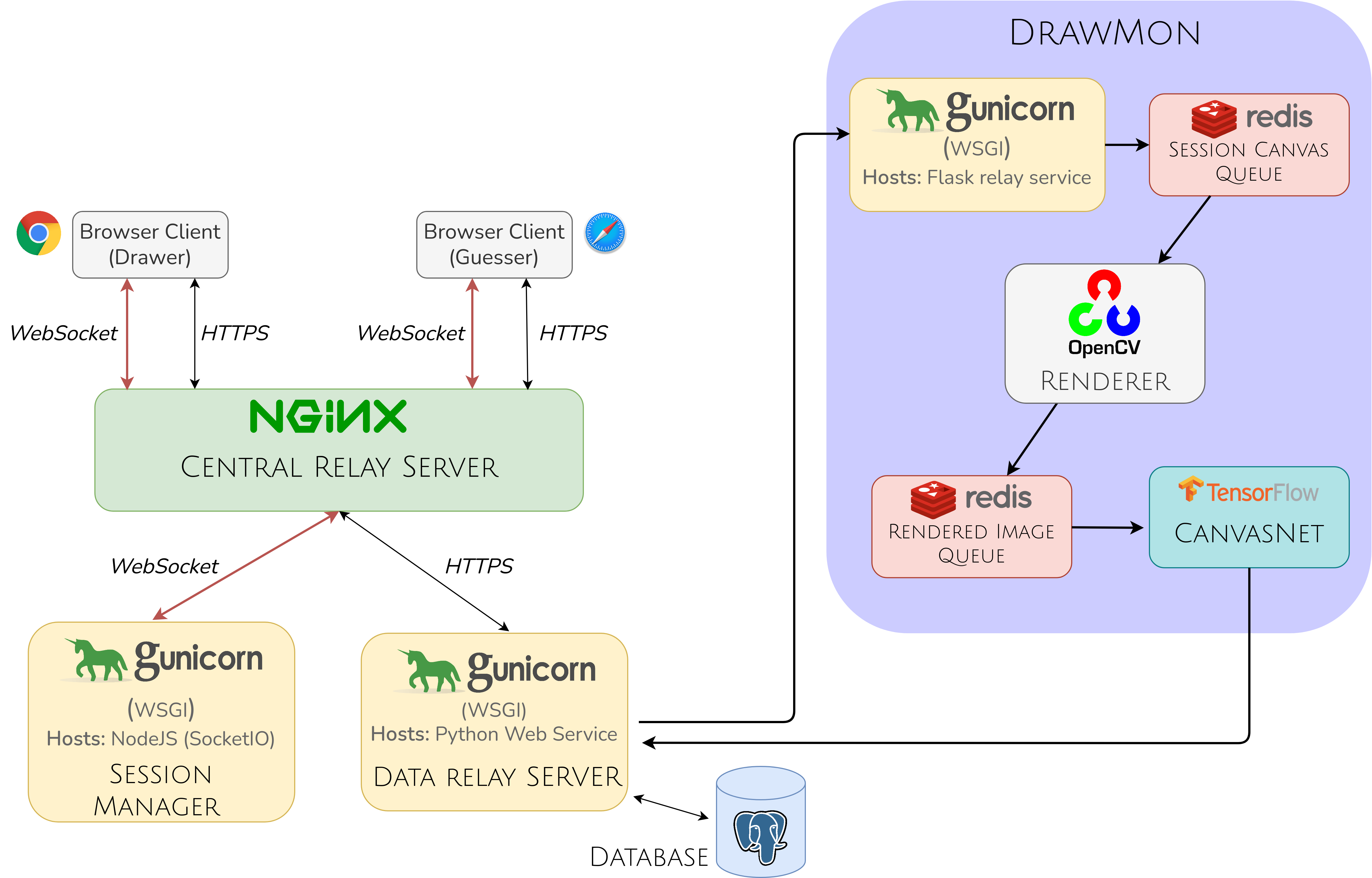
CanvasNet: a model for detecting atypical sketch instances
CanvasNet processes the rendered image as input and outputs a list of atypical activities (if any) along with associated meta-information (atypical content category, 2-D spatial location).
DrawMon in Action
Paper
- PDF: Paper
- arXiv: Coming soon!
- ACMMM-2022: Coming soon!
Code
The code for this work is available on GitHub!
Link: pictionary-cvit/drawmon
Acknowledgements
We wish to acknowledge grant from KCIS - TCS foundation.
Bibtex
Please consider citing the following works if you make use of our work:
@InProceedings{DrawMonACMMM2022,
author="Bansal, Nikhil
and Gupta, Kartik
and Kannan, Kiruthika
and Pentapati, Sivani
and Sarvadevabhatla, Ravi Kiran",
title="DrawMon: A Distributed System for Detection of Atypical Sketch Content in Concurrent Pictionary Games",
booktitle = "ACM conference on Multimedia (ACMMM)",
year="2022"
}