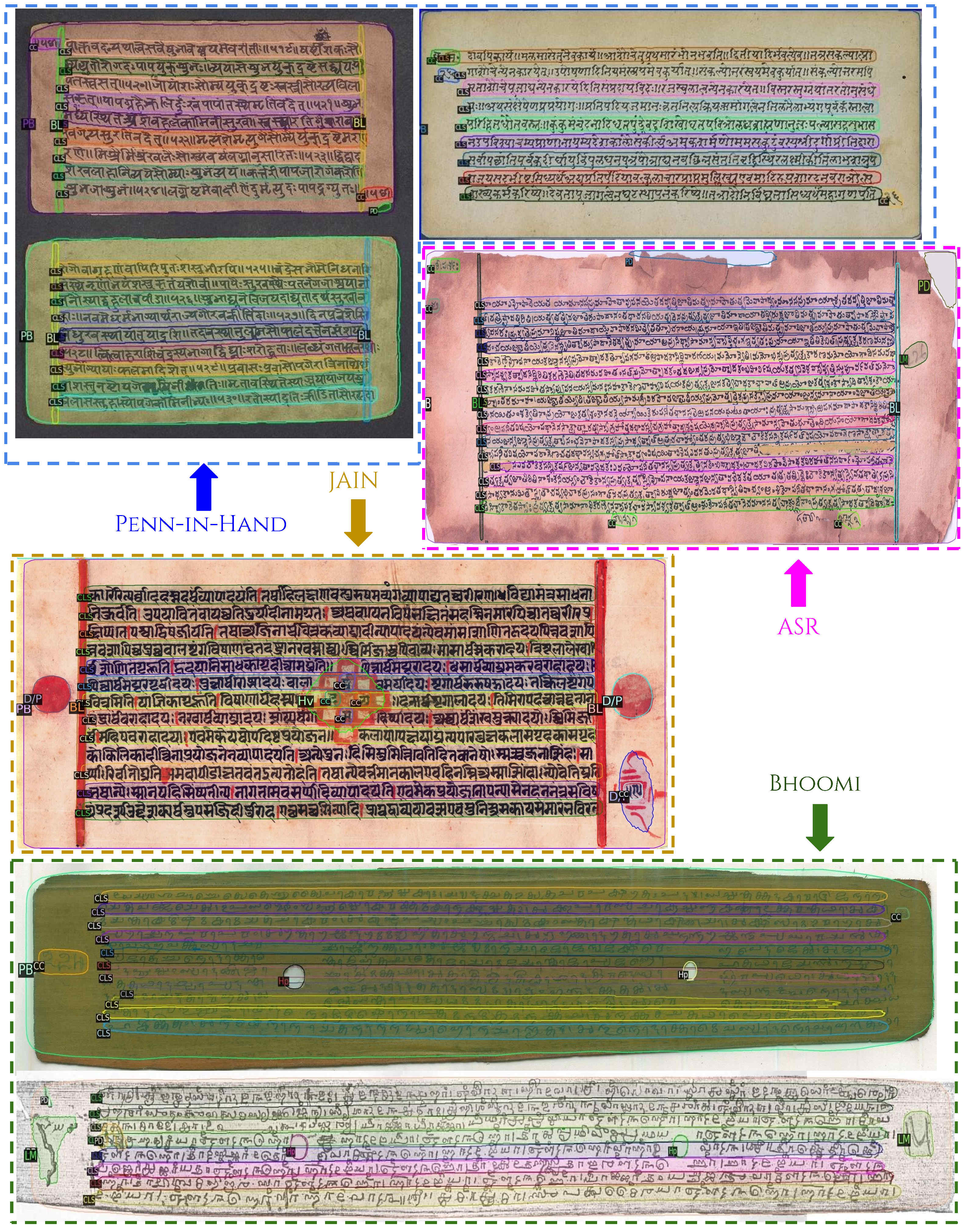
PALMIRA: A Deep Deformable Network for Instance Segmentation of Dense and Uneven Layouts in Handwritten Manuscripts
Abstract
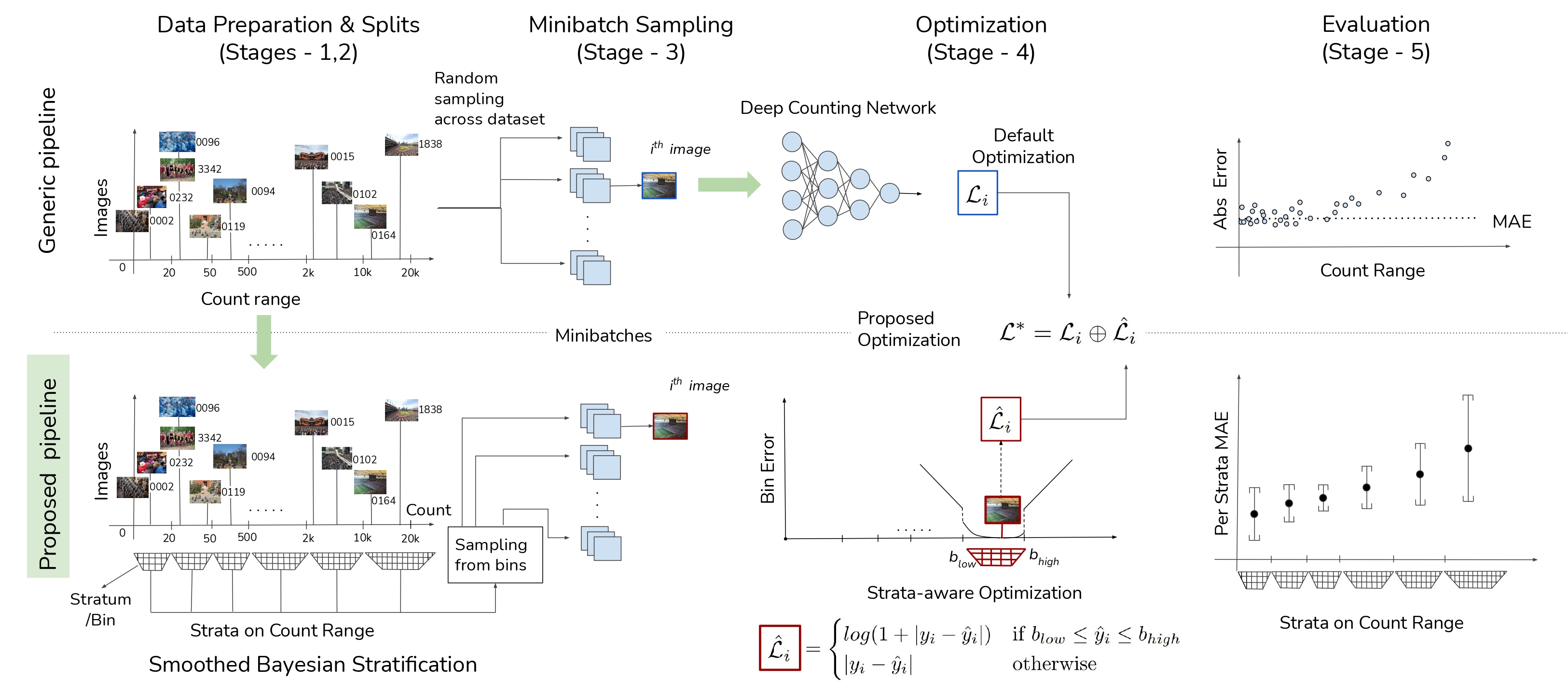
Architecture
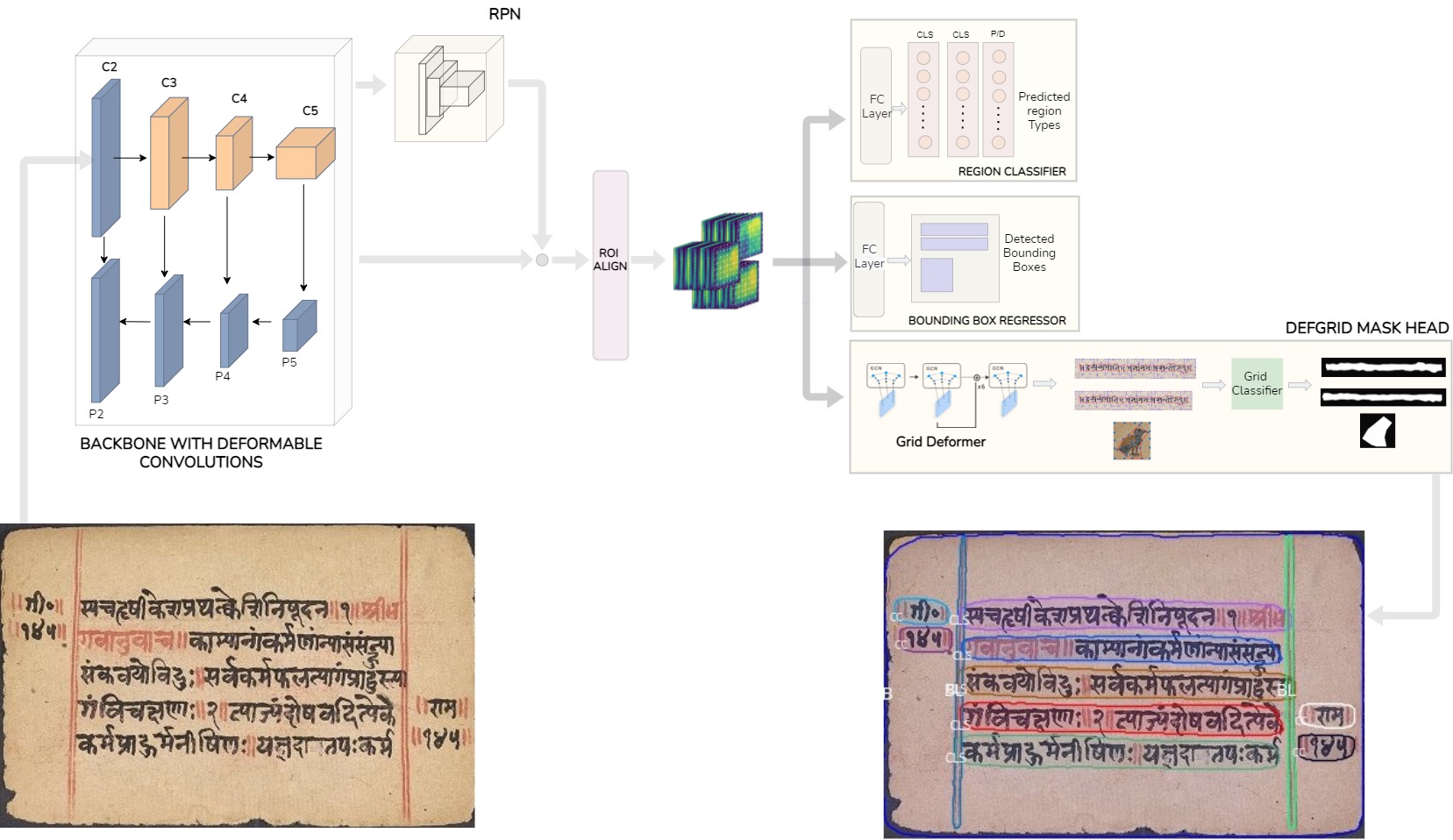 The PALMIRA architecture. The orange blocks in the backbone are deformable convolutions. A closer look at the DefGrid Mask Head and the Backbone alteration is provided below in the Network Architecture section.
The PALMIRA architecture. The orange blocks in the backbone are deformable convolutions. A closer look at the DefGrid Mask Head and the Backbone alteration is provided below in the Network Architecture section. Highlights
Network Architecture
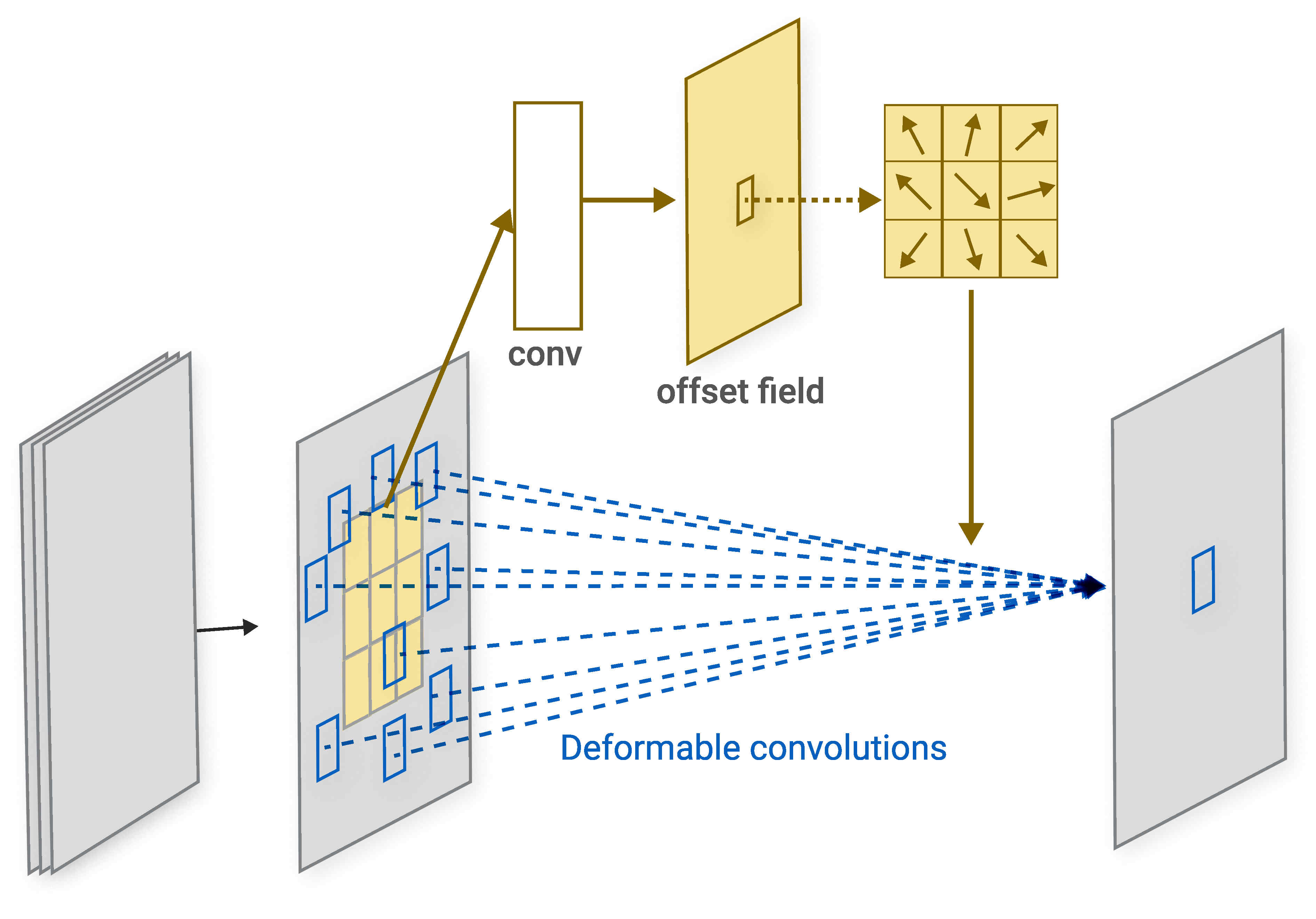
Deformable Convolutions provide a way to determine suitable local 2D offsets for the default spatial sampling locations
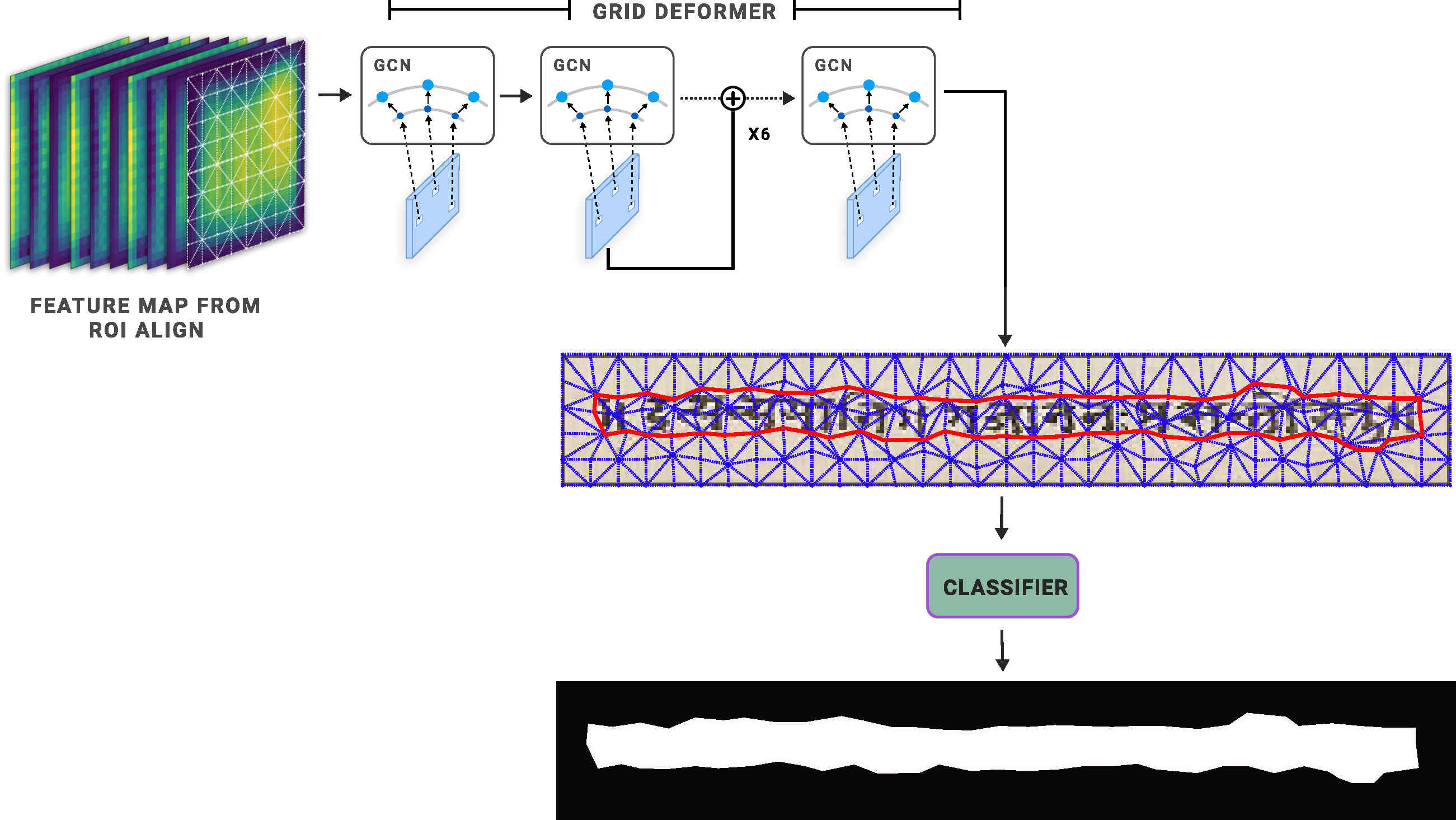
The Deformable Grid Mask Head network is optimized to predict the offsets of the grid vertices such that a subset of edges incident on the vertices form a closed contour which aligns with the region boundary.

Results
Layout predictions by Palmira on representative test set documents from Indiscapes2 dataset. Note that the colors are used to distinguish region instances. The region category abbreviations are present at corners of the regions.
A comparative illustration of region-level performance. Palmira’s predictions are in red. Predictions from the best model among baselines (BoundaryPreserving Mask-RCNN) are in green. Ground-truth boundary is depicted in white.

Layout predictions by Palmira on out-of-dataset handwritten Manuscripts

Citation
@inproceedings{sharan2021palmira,
title = {PALMIRA: A Deep Deformable Network for Instance Segmentation of Dense and Uneven Layouts in Handwritten Manuscripts},
author = {Sharan, S P and Aitha, Sowmya and Amandeep, Kumar and Trivedi, Abhishek and Augustine, Aaron and Sarvadevabhatla, Ravi Kiran},
booktitle = {International Conference on Document Analysis and Recognition,
{ICDAR} 2021},
year = {2021},
}
Contact
If you have any question, please contact Dr. Ravi Kiran Sarvadevabhatla at
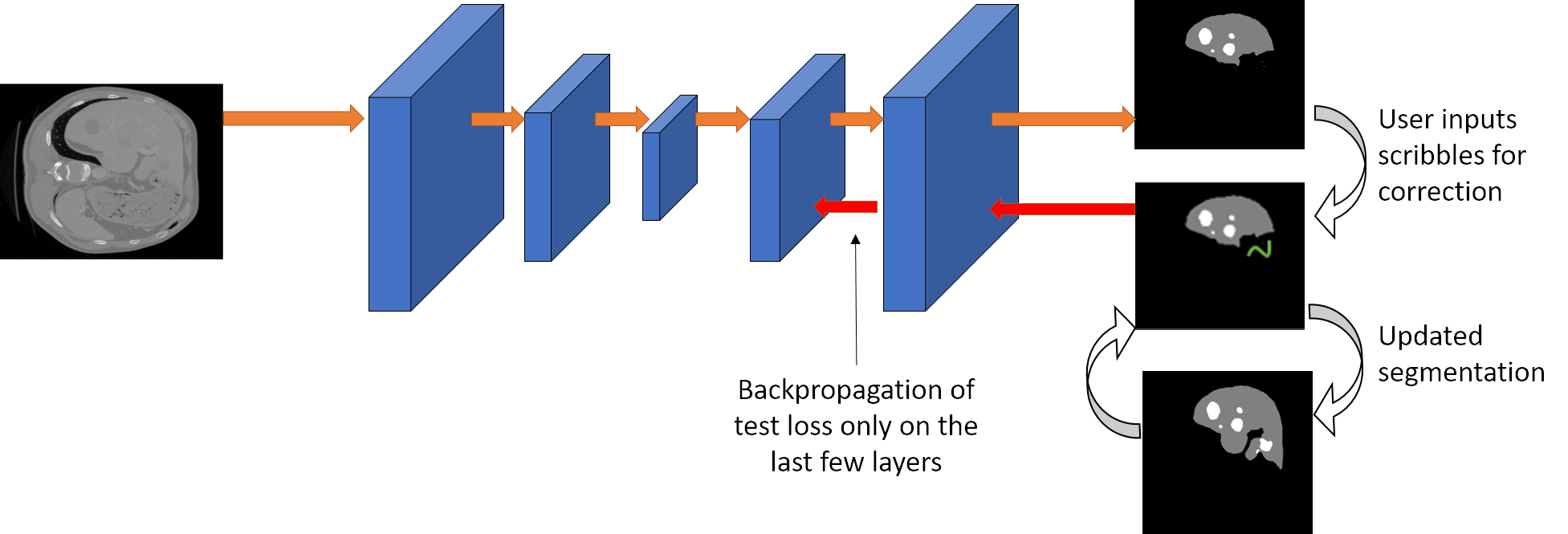
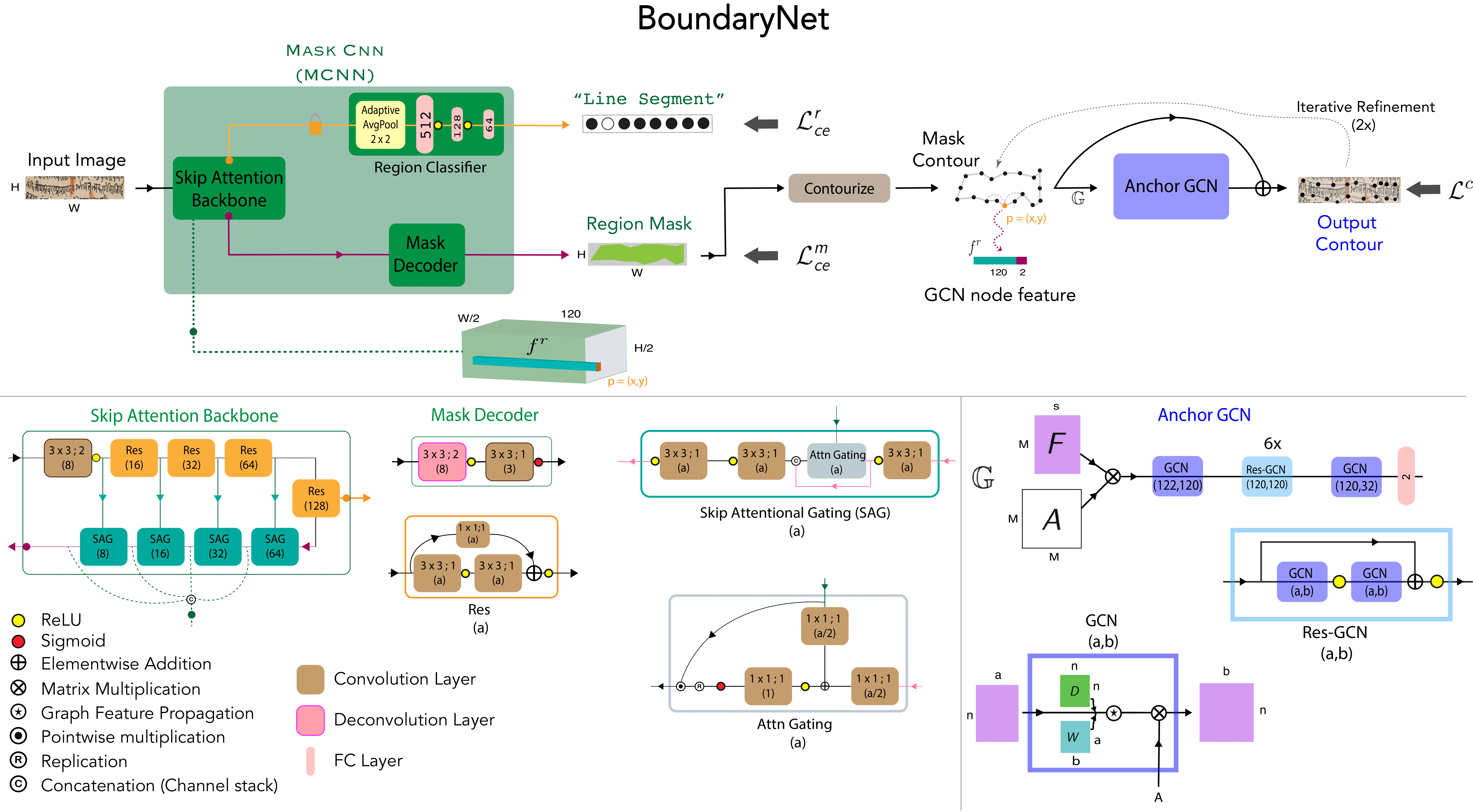 The architecture of BoundaryNet (top) and various sub-components (bottom). The variable-sized H×W input image is processed by Mask-CNN (MCNN) which predicts a region mask estimate and an associated region class. The mask’s boundary is determined using a contourization procedure (light brown) applied on the estimate from MCNN. M boundary points are sampled on the boundary. A graph is constructed with the points as nodes and edge connectivity defined by 6 k-hop neighborhoods of each point. The spatial coordinates of a boundary point location p = (x, y) and corresponding back- bone skip attention features from MCNN f^r are used as node features for the boundary point. The feature-augmented contour graph G = (F, A) is iteratively
processed by Anchor GCN to obtain the final output contour points defining the region boundary.
The architecture of BoundaryNet (top) and various sub-components (bottom). The variable-sized H×W input image is processed by Mask-CNN (MCNN) which predicts a region mask estimate and an associated region class. The mask’s boundary is determined using a contourization procedure (light brown) applied on the estimate from MCNN. M boundary points are sampled on the boundary. A graph is constructed with the points as nodes and edge connectivity defined by 6 k-hop neighborhoods of each point. The spatial coordinates of a boundary point location p = (x, y) and corresponding back- bone skip attention features from MCNN f^r are used as node features for the boundary point. The feature-augmented contour graph G = (F, A) is iteratively
processed by Anchor GCN to obtain the final output contour points defining the region boundary.
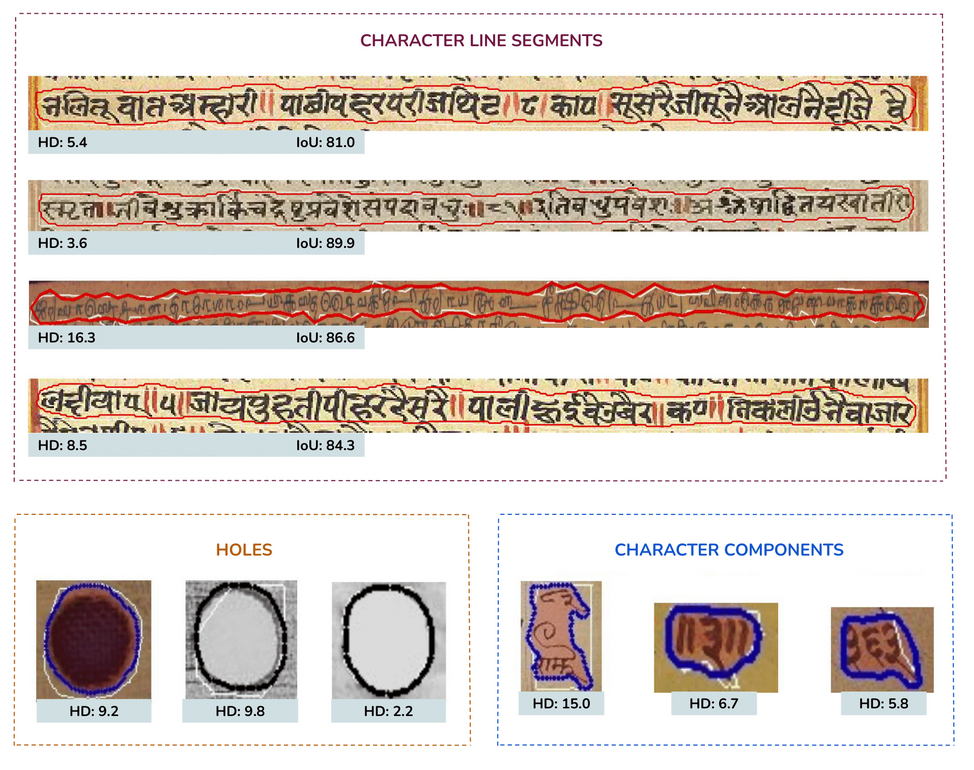

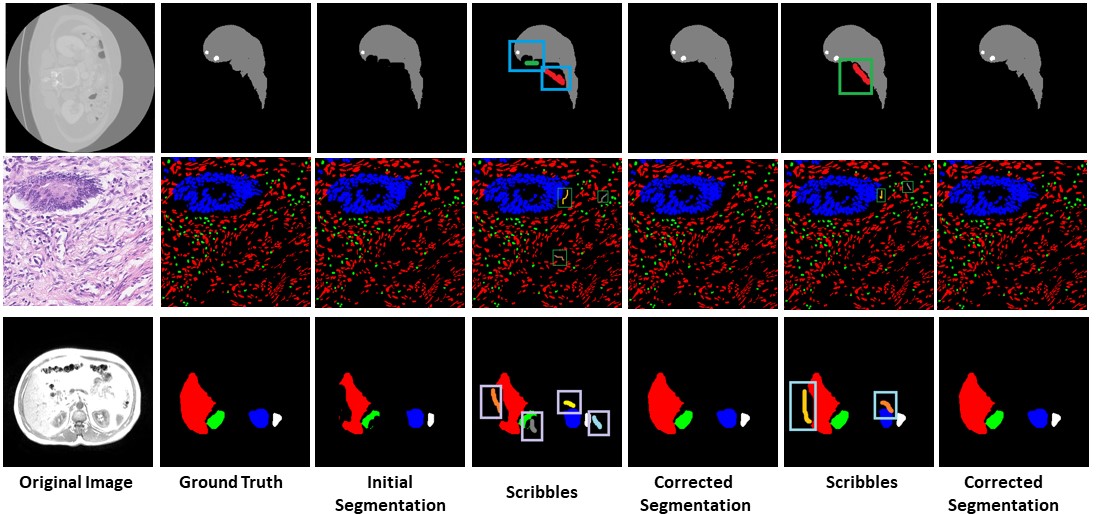
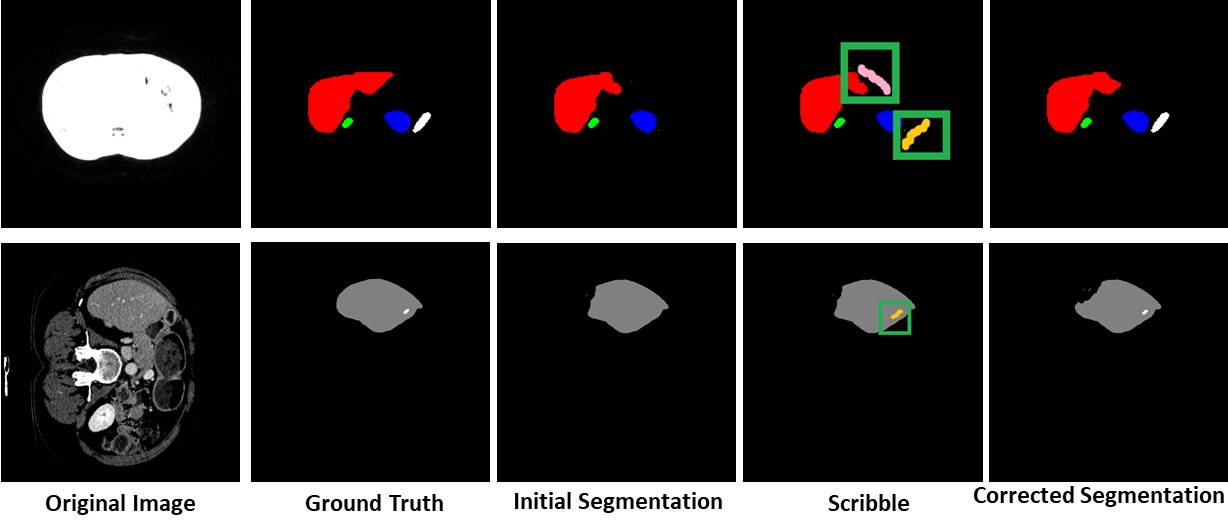
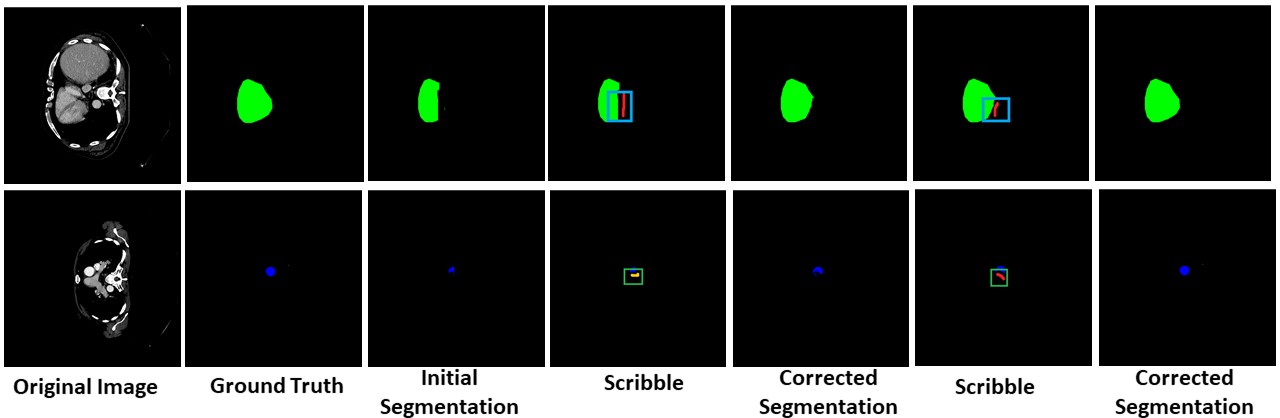
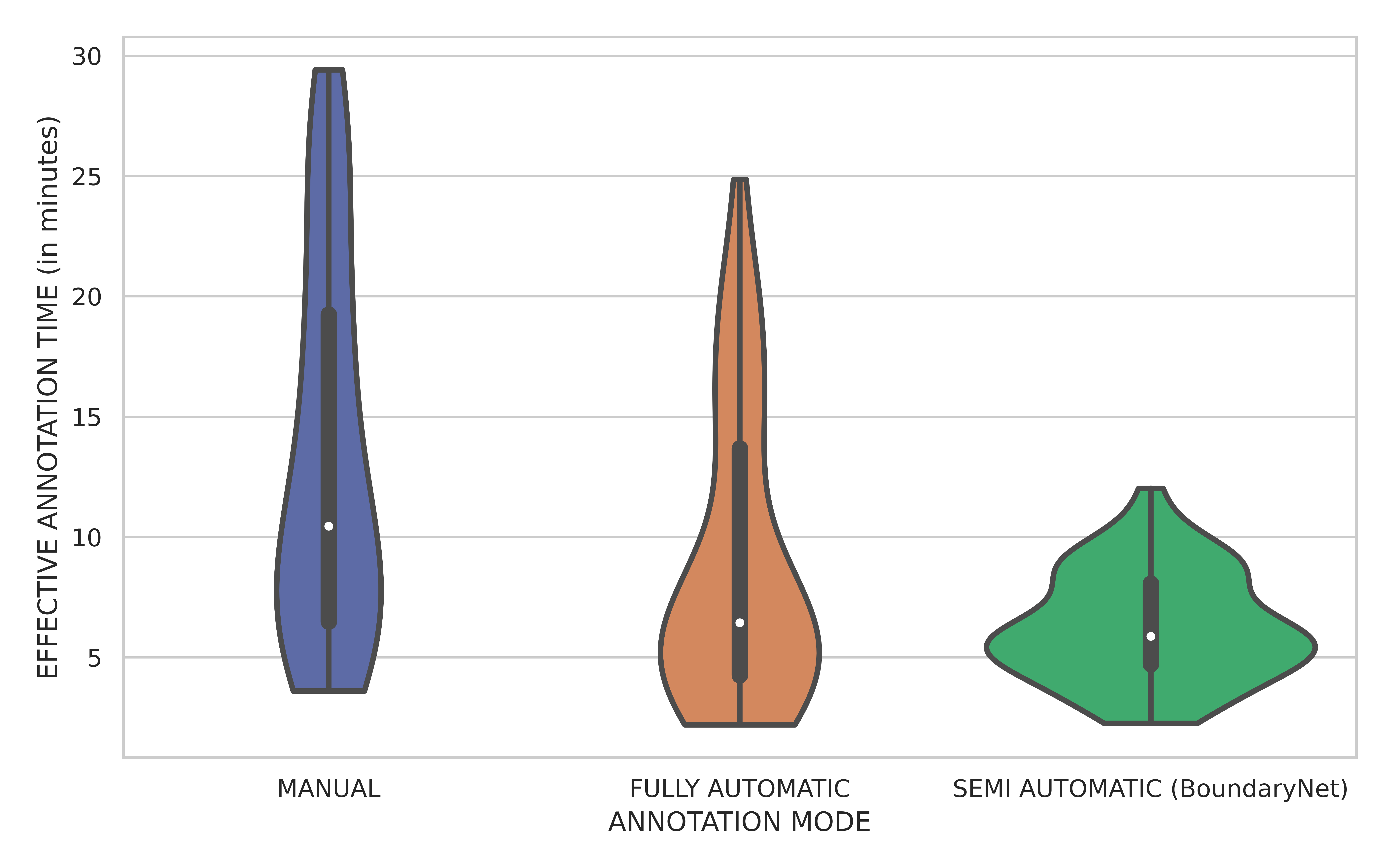 A small scale experiment was conducted with real human annotators in the loop to determine BoundaryNet utility in a practical setting. The annotations for a set of images were sourced using HINDOLA document annotation system in three distinct modes: Manual Mode (hand-drawn contour generation and region labelling), Fully Automatic Mode (using an existing instance segmentation approach- Indiscapes with post-correction using the annotation system) and Semi-Automatic Mode (manual input of region bounding boxes which are subsequently sent to BoundaryNet, followed by post-correction). For each mode, we recorded the end-to-end annotation time at per-document level, including manual correction time (Violin plots shown in the figure). BoundaryNet outperforms
other approaches by generating superior quality contours which minimize post-inference manual correction burden.
A small scale experiment was conducted with real human annotators in the loop to determine BoundaryNet utility in a practical setting. The annotations for a set of images were sourced using HINDOLA document annotation system in three distinct modes: Manual Mode (hand-drawn contour generation and region labelling), Fully Automatic Mode (using an existing instance segmentation approach- Indiscapes with post-correction using the annotation system) and Semi-Automatic Mode (manual input of region bounding boxes which are subsequently sent to BoundaryNet, followed by post-correction). For each mode, we recorded the end-to-end annotation time at per-document level, including manual correction time (Violin plots shown in the figure). BoundaryNet outperforms
other approaches by generating superior quality contours which minimize post-inference manual correction burden.