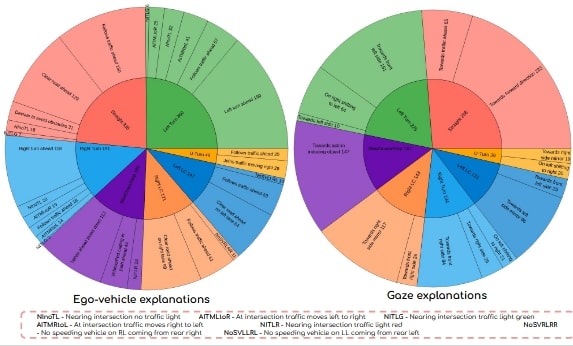
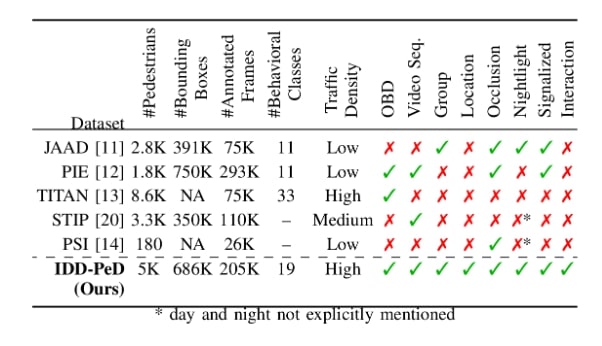
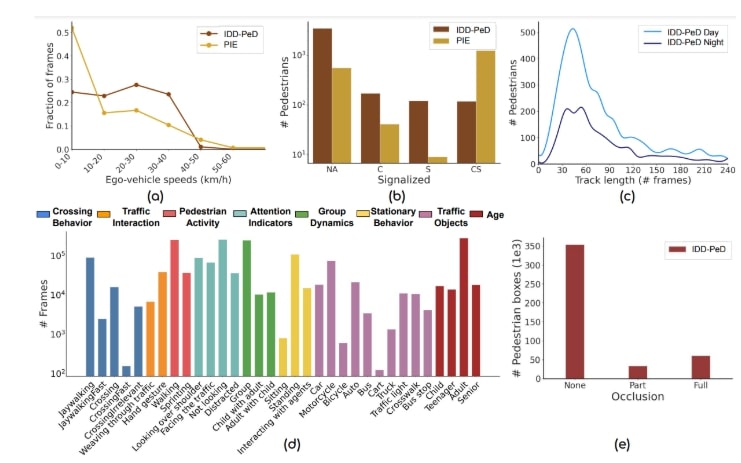
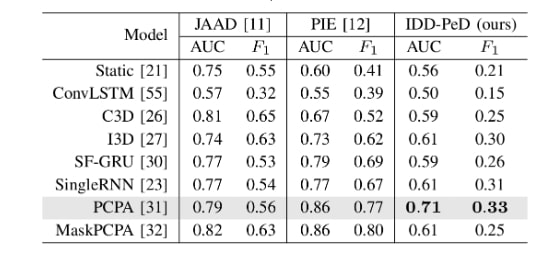
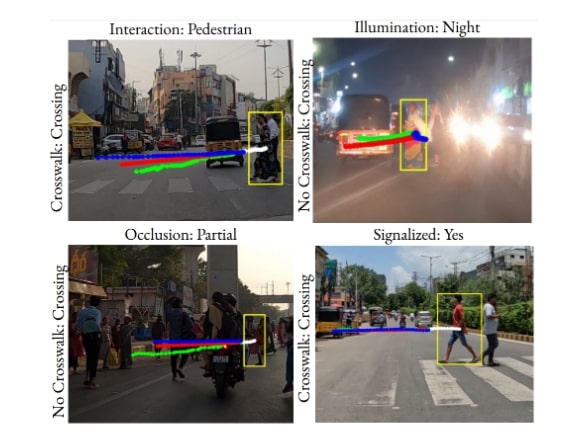
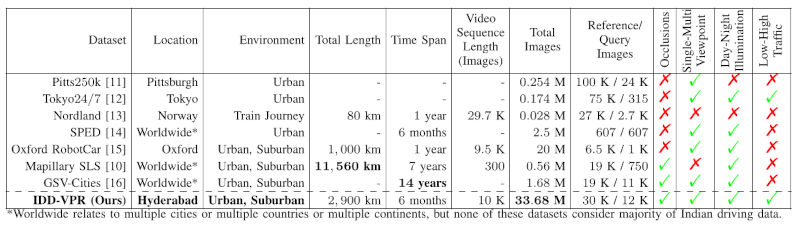
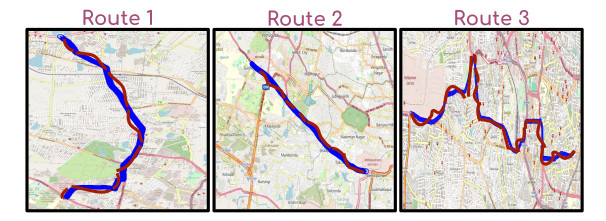
What is there in an Indian Thali?
[Paper] [Supplementary] [GitHub]
[Indian Thali Dataset] [
Weight Estimation Dataset
]

From Thali to Nutritional Summary: Our automated pipeline takes a single thali image (a) and performs segmentation with classification (b), raw weight estimation (c), and finally, a complete nutritional summary (d).
Project Teaser: Animated demonstration of our pipeline, showing the transformation from a thali image to a nutritional summary.
Abstract
Automated dietary monitoring solutions face significant challenges with culturally diverse, multi-dish meals, where traditional approaches fail. Most systems are tailored to western foods and struggle with the overlapping textures and cultural specificity of dishes like Indian Thalis, which contain 5-10 distinct items. We present Food Scanner, a novel, end-to-end pipeline with retraining-free segmentation & prototype-based classification, plus a lightweight trainable weight-regression head for automated nutrition estimation from a single image. Our approach requires no class-specific retraining, enabling rapid adaptation to new dishes. To enable this study, we contribute two datasets: a multi-view Indian Thali Dataset (ITD) of 796 plates (7,900 images) and a Weight Estimation Dataset (WED) of 267 plates (1,394 images) with gram-level annotations. Our system offers a scalable, culturally adaptable solution for diverse food environments.
Why is an Indian Thali so Challenging?
Automated food analysis of Indian cuisine is notoriously difficult due to several unique visual challenges that break standard recognition models:
- Occlusion and Overlapping: Dishes are served in close proximity, with items like rice often hidden under curries (e.g., 'Dal mixed with rice').
- Deformable Structures: Foods like 'Roti' can be folded or flat, drastically changing their visual appearance.
- High Inter-Class Similarity: Many different dishes share similar colors and textures, making them hard to distinguish (e.g., 'Sambar' vs. 'Dal Makhani' vs. 'Tomato Rasam').
- High Intra-Class Variation: The *same* dish can look completely different based on preparation, ingredients, or garnish (e.g., different preparations of 'Dal' or 'Baingan Curry').

The Food Scanner Pipeline
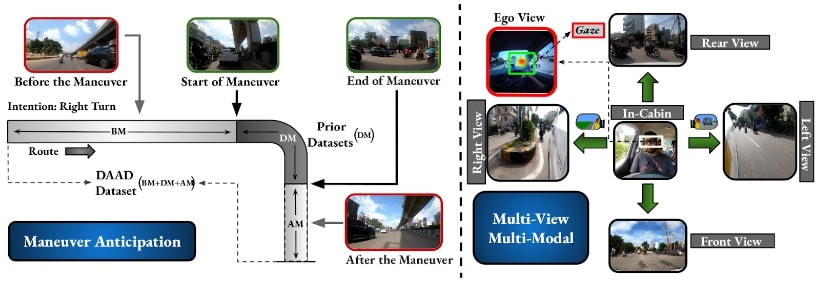
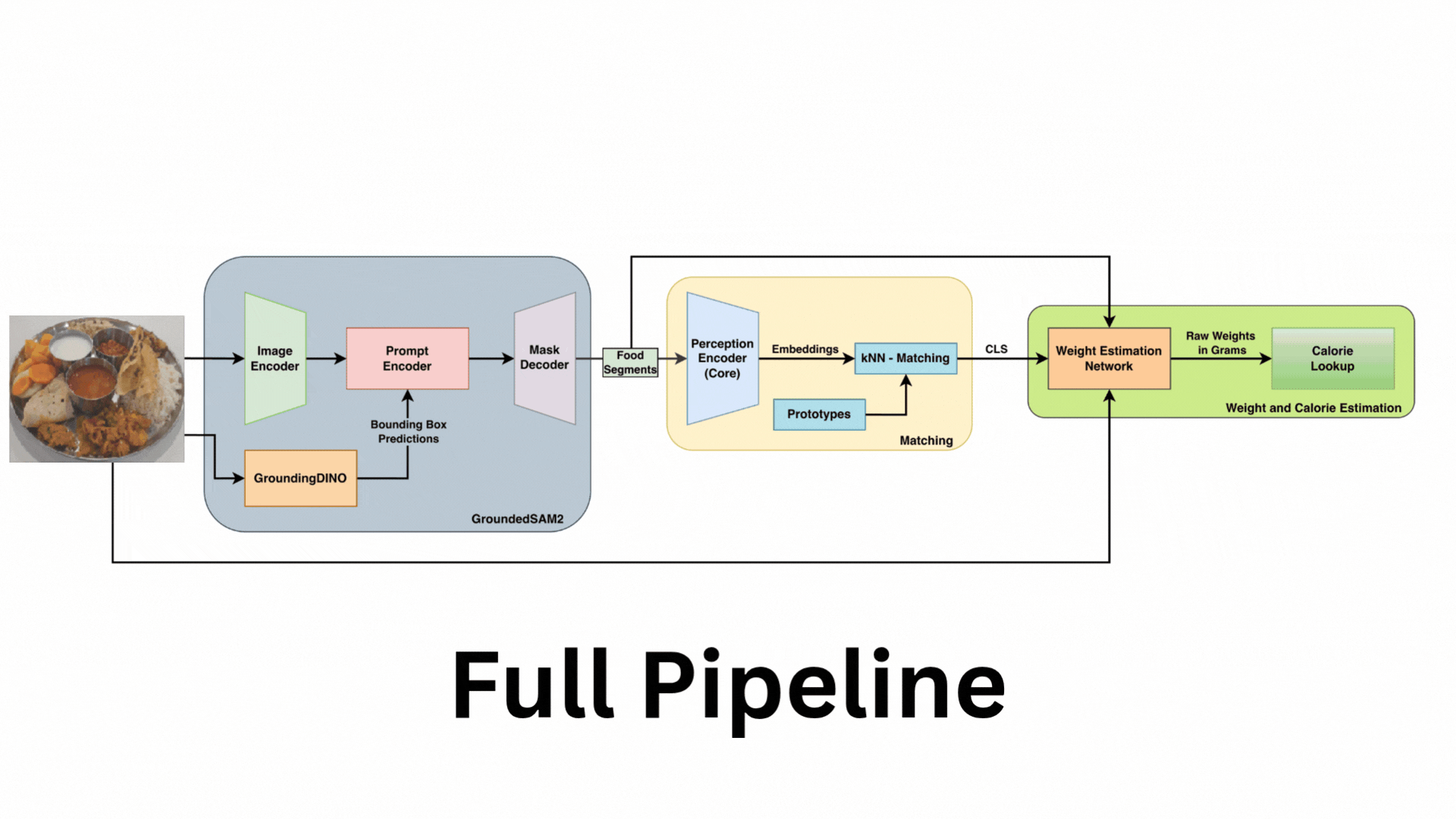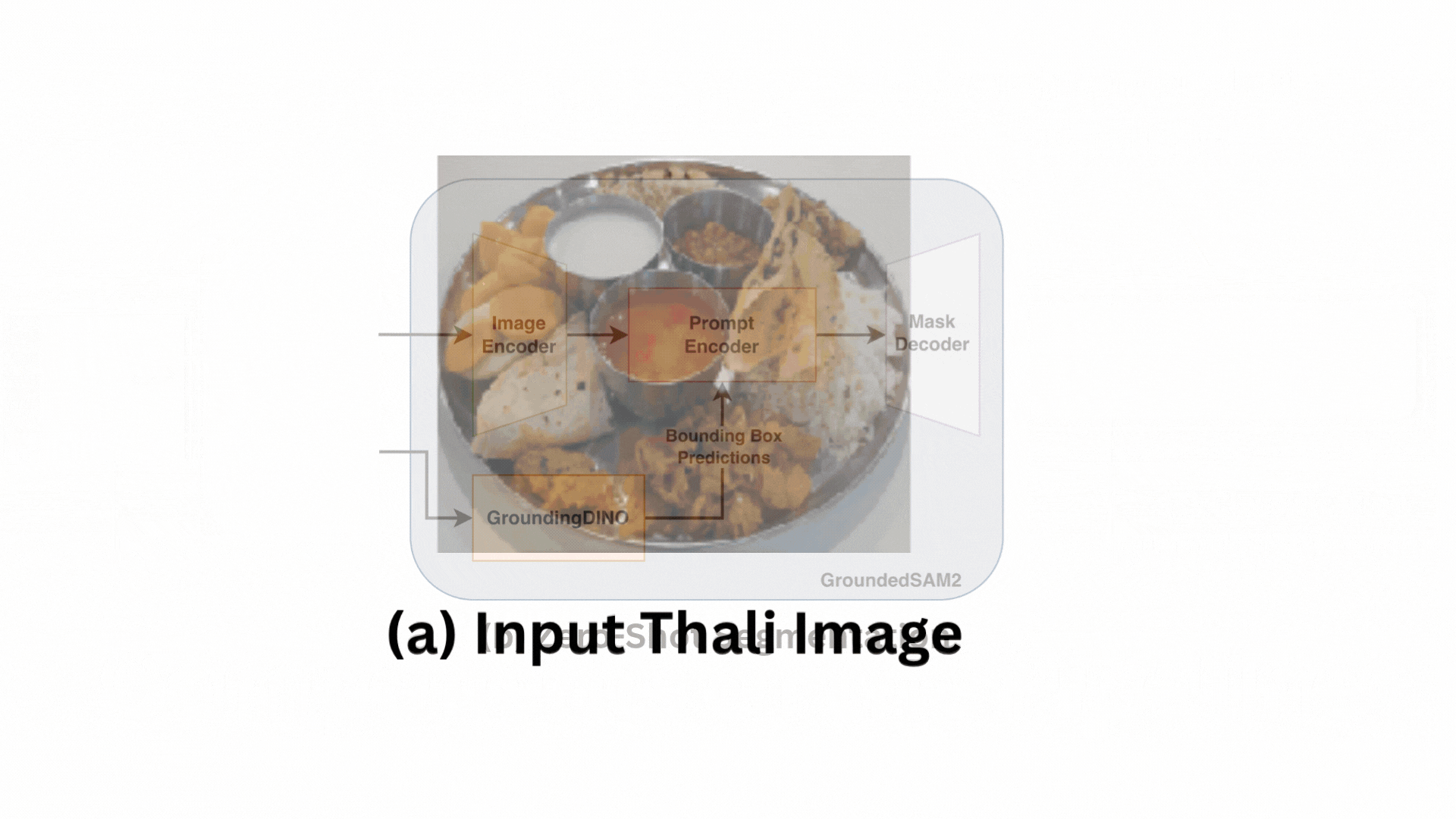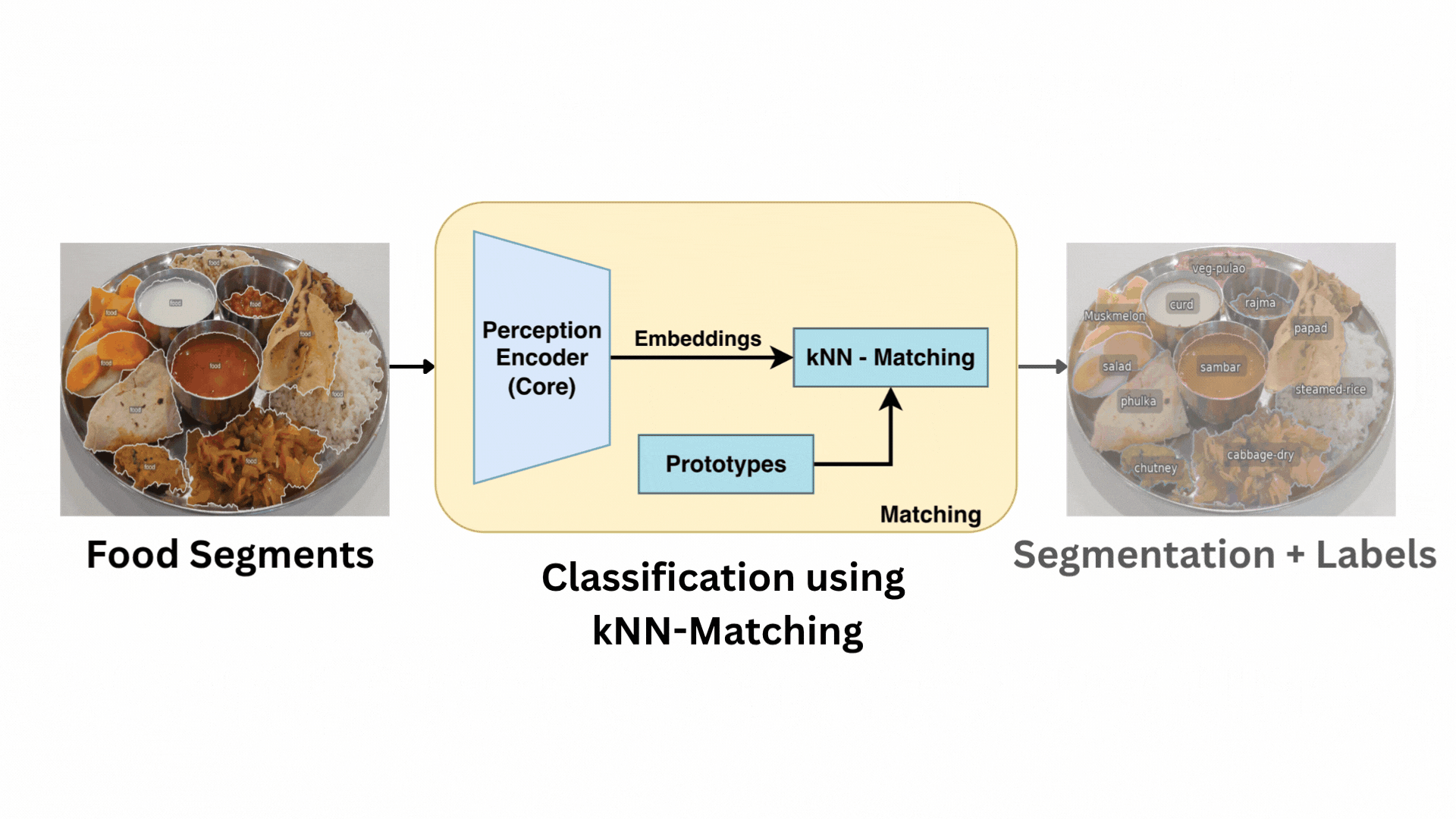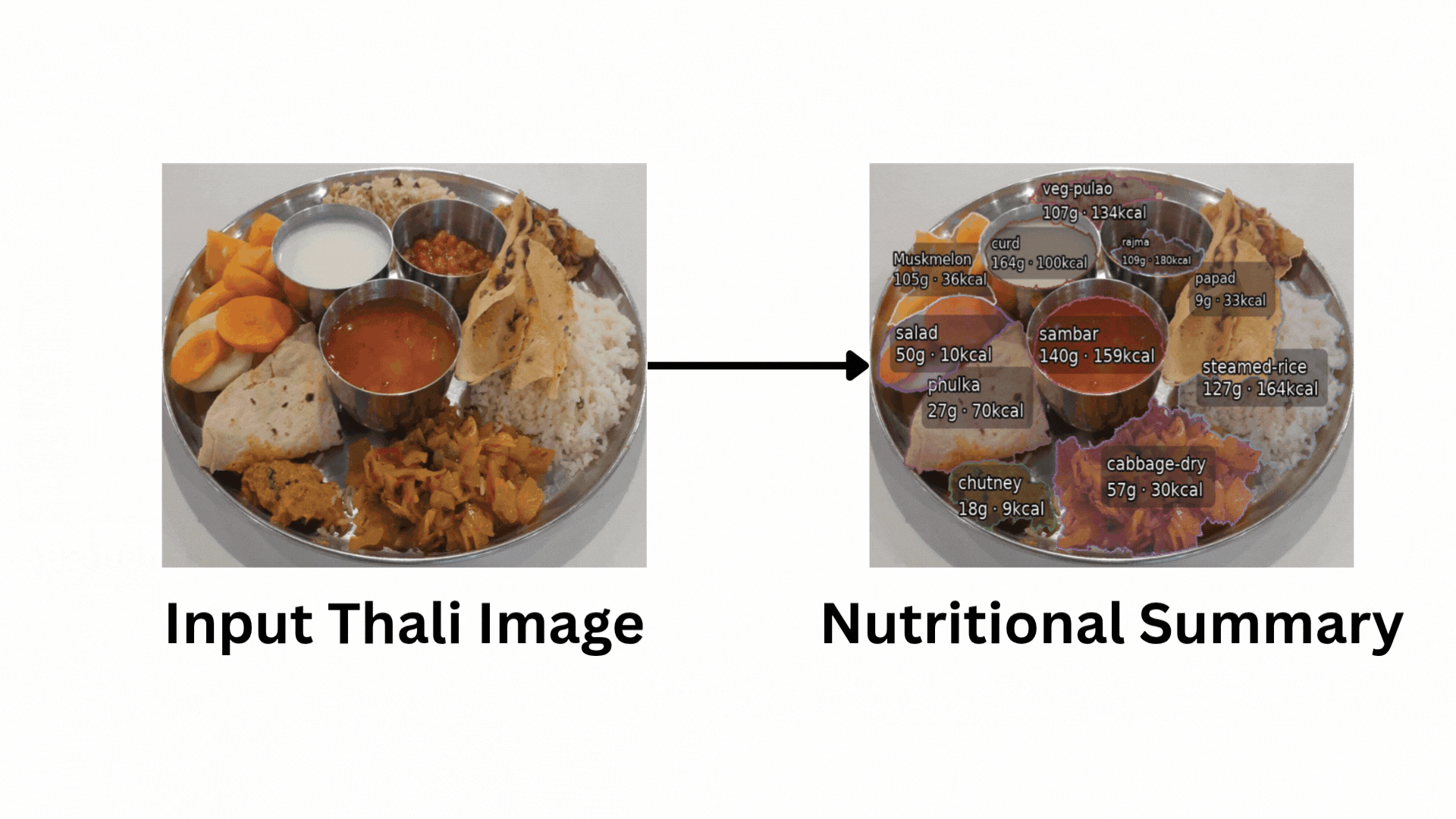
Our system is a modular, four-stage pipeline designed for scalability and real-world deployment without needing constant retraining.
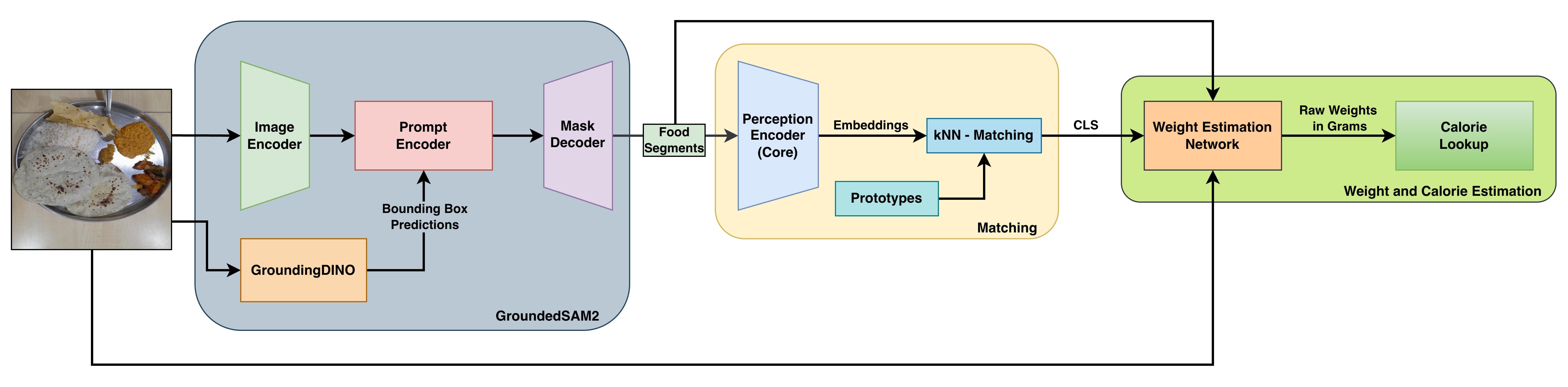
The complete Food Scanner architecture, from segmentation with GroundedSAM2 to kNN matching and final weight/calorie estimation.
1. Zero-Shot Segmentation
We use GroundedSAM2 (Grounded-SAM-2) with a single, generic prompt "food" to generate class-agnostic masks for all edible items on the plate. This requires no fine-tuning or per-class annotation.
2. Retraining-Free Classification
Each food segment is identified using a prototype-based k-Nearest Neighbors (kNN) matching system. We use a Perception Encoder (PE) to create visual embeddings for each segment. These are then compared (using cosine similarity) against a "prototype gallery" of known dishes for that day's menu. This allows new dishes to be added "on-the-fly" just by adding a few prototype images, completely eliminating the need for retraining.
3. Lightweight Weight Regression
Once labeled, each food region is passed to our FusionWeightNet (built on a ResNet-50 backbone) to predict its weight in grams. This is the only trainable component in our pipeline, and it achieves a mean absolute error of ~14-15 grams.
4. Nutritional Computation
The predicted gram weights are converted into calories, protein, carbohydrates, and fats using a pre-compiled nutritional lookup table, providing a complete per-dish and per-plate summary.
Data Capture Setup
To build our datasets, we designed a multi-view capture rig to photograph each thali from 5 distinct viewpoints. This setup ensures we capture diverse visual cues, which is crucial for training a robust weight estimation model that understands food volume from 2D images.

Our multi-view capture setup (left) and camera position schematic (right) used for both datasets.
Our Datasets
A key contribution of this work is the creation of two large-scale, multi-view datasets for Indian food analysis.
- Indian Thali Dataset (ITD): The first dataset for segmentation, containing 7,900 images from 796 unique plates, covering 50 dishes. Each image is annotated with dense, pixel-level masks.
- Weight Estimation Dataset (WED): The second dataset for weight regression, containing 1,394 images from 267 plates, covering 41 dishes. Each food item on the plate has a corresponding precise gram-level weight measurement.

Sample 8x8 grid showing images from the Indian Thali Dataset (left 4 columns) and Weight Estimation Dataset (right 4 columns).
A video walkthrough demonstrating the scale, diversity, and annotation quality of our datasets.
Real-World Deployment: The Food Scanner Kiosk
We validated our pipeline by deploying it as a real-world "Food Scanner Kiosk" in a university mess hall at IIIT Hyderabad. Users can place their thali in the kiosk, which captures an image and provides an immediate, on-screen nutritional breakdown.
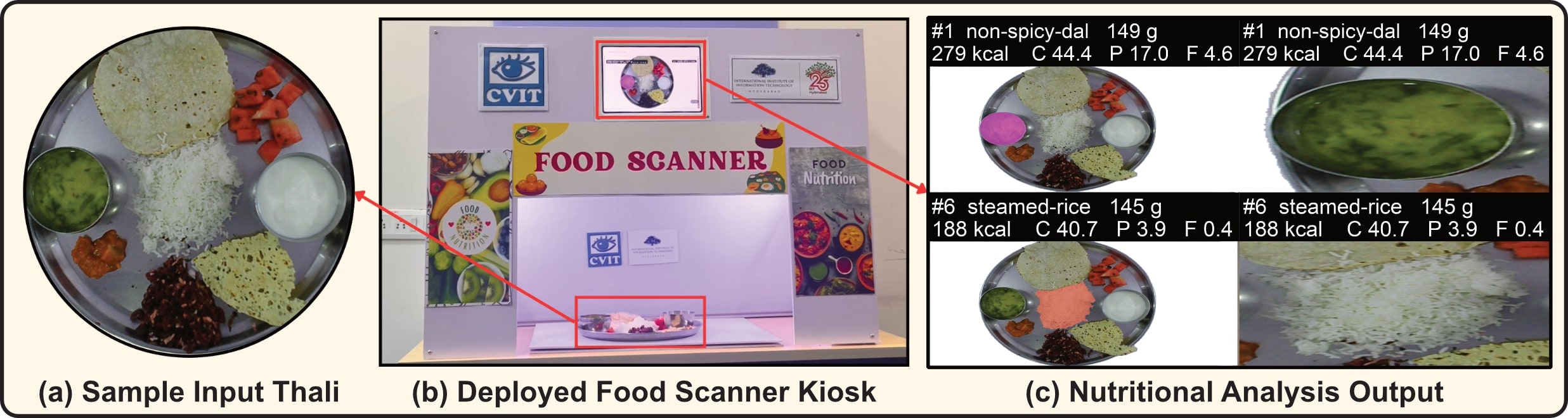
The deployed system: (a) A sample thali input, (b) The self-service Food Scanner Kiosk, and (c) The final nutritional analysis output displayed to the user.
Live Kiosk Demo: Watch the deployed Food Scanner Kiosk in action, providing instant nutritional analysis from a real thali image.
Contact: