Biological Vision
Introduction
The perceptual mechanisms used by different organisms to negotiate the visual world are fascinatingly diverse. Even if we consider only the sensory organs of vertebrates, such as eye, there is much variety. Several disciplines have approached the problem of investigating how sensory, motors and central visual systems function and are oganised. Area of biological vision aims to build a computational understanding of various brian mechanisms. Synergy between biological and computer vision research can be found in low-level vision. Substantial insights about the processes for extracting colour, edge, motion and spatial frequency information from images have come from combining computational and neuro-physiological constraints. Understanding of human perception/vision is said to be an early step towards indetifying objects and understanding of scene.
Work Undertaken
:: Towards Understanding Texture Processing ::
A fundamental goal of texture research is to develop automated computational methods for retrieving visual information and understanding image content based on textural properties in images. A synergy between biological and computer vision research in low-level vision can give substantial insights about the processes for extracting color, edge, motion, and spatial frequency information from images. In this thesis, we seek to understand the texture processing that takes place in low level human vision in order to develop new and effective methods for texture analysis in computer vision. The different representations formed by the early stages of HVS and visual computations carried out by them to handle various texture patterns is of interest. Such information is needed to identify the mechanisms that can be use in texture analysis tasks. (more detail...)
:: Biologically Inspired Interest Point Operator ::
 Interest point operators (IPO) are used extensively for reducing computational time and improving the accuracy of several complex vision tasks such as object recognition or scene analysis. SURF, SIFT, Harris,Corner points etc., are popular examples. Though there exists a large number of IPOs in the vision literature, most of them rely on low level features such as color,edge orientation etc., making them sensitive to degradation in the images.
Interest point operators (IPO) are used extensively for reducing computational time and improving the accuracy of several complex vision tasks such as object recognition or scene analysis. SURF, SIFT, Harris,Corner points etc., are popular examples. Though there exists a large number of IPOs in the vision literature, most of them rely on low level features such as color,edge orientation etc., making them sensitive to degradation in the images.
Human vision systems (HVS) perform these tasks with seemingly little effort and are robust to such degradation by employing spatial attention mechanisms to reduce the computational burden. Extensive studies of these spatial attention mechanisms have led to several computational models (eg. Itti, Koch). However, very few models have found successful applications in computer vision related tasks partly owing to their prohibitive
Computational attention systems either have used top-down or bottom-up information. Using both types of information is an attractive choice for top-down knowledge is quite helpful particularly when images are degraded [Antonio Torralba]. Our work is focused on developing a robust biologically-inspired IPO capable of utilizing top-down knowledge. The operator will be tested as a feature detector /descriptor for a Monocular Visual SLAM.
Antonio Torralba, Contextual Priming for Object Detection, IJCV,Vol.53, 2,2003,Pages:169--191.
Laurent Itti, Christof Koch, A saliency based search mechanism for overt and covert shifts of visual attention,Vision Research,Vol.40,2000,Pages: 1489--1506
Current under-going Projects
- Medical Image Reconstruction on Hexagonal Grid
- Computational Understanding of Medical Image Interpretation by Expert
Related Publications
N.V. Kartheek Medathati, Jayanthi Sivaswamy - Local Descriptor based on Texture of Projections Proceedings of Seventh Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP'10),12-15 Dec. 2010,Chennai, India. [PDF]
Joshi Datt Joshi, Saurabh Garg and Jayanthi Sivaswamy - Script Identification from Indian Documents, Proceedings of IAPR Workshop on Document Analysis Systems (DAS 2006), Nelson, pp.255-267. [PDF]
Gopal Datt Joshi, Saurabh Garg and Jayanthi Sivaswamy - A Generalised Framework for Script Identification Proc. of International Journal for Document Analysis and Recognition(IJDAR), 10(2), pp.55-68, 2007. [PDF]
Gopal Datt Joshi and Jayanthi Sivaswamy - A Computational Model for Boundary Detection, 5th Indian Conference on Computer Vision, Graphics and Image Processing (ICVGIP), Madurai, India, LNCS 4338 pp.172-183, 2006. [PDF]
Gopal Datt Joshi, and Jayanthi Sivaswamy - A Simple Scheme for Contour Detection, Proceedings of International Conference on Computer Vision and Applications (VISAP 2006), Setubal. [PDF]
Gopal Datt Joshi , and Jayanthi Sivaswamy - A Multiscale Approach to Contour Detection, Proceedings of International Conference on Cognition and Recognition (ICCR), pp. 183-193, Mysore, 2005. [PDF]
L.Middleton and J. Sivaswamy, Hexagonal Image Processing, Springer Verlag, London, 2005, ISBN: 1-85233-914-4. [PDF]
L. Middleton and J. Sivaswamy - A Framework for Practical Hexagonal-Image Processing, Journal of Electronic Imaging, Vol. 11, No. 1, January 2002, pp. 104--114. [PDF]
Associated People
- Gopal Datt Joshi
- N. V. Kartheek
- Varun Jampani
- Prof. Jayanthi Sivaswamy

 The scene representation using multiple Depth Images contains redundant descriptions of common parts. Our Compression methods aim at exploiting this redundancy for a compact representation. The various kinds of compression algorithms tried are ::
The scene representation using multiple Depth Images contains redundant descriptions of common parts. Our Compression methods aim at exploiting this redundancy for a compact representation. The various kinds of compression algorithms tried are ::
 Features of The Garuda System ::
Features of The Garuda System ::
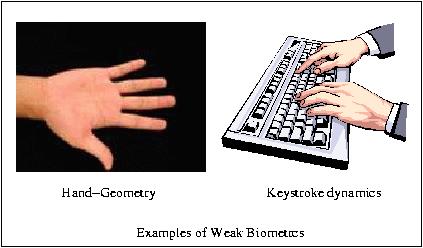
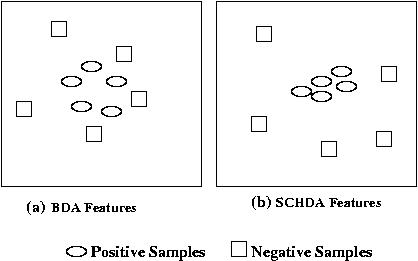 Due to the low discriminating content of the weak biometric traits, they show poor performance during verification. We have developed a novel feature selection technique called Single Class Hierarchical Discriminant Analysis (SCHDA), specifically for authentication purpose in biometric systems. SCHDA builds an optimal user-specific discriminant space for each individual where the samples of the claimed identity are well-separated from the samples of all the other users.
Due to the low discriminating content of the weak biometric traits, they show poor performance during verification. We have developed a novel feature selection technique called Single Class Hierarchical Discriminant Analysis (SCHDA), specifically for authentication purpose in biometric systems. SCHDA builds an optimal user-specific discriminant space for each individual where the samples of the claimed identity are well-separated from the samples of all the other users.
{kind=link}