The IIIT-CFW dataset
About
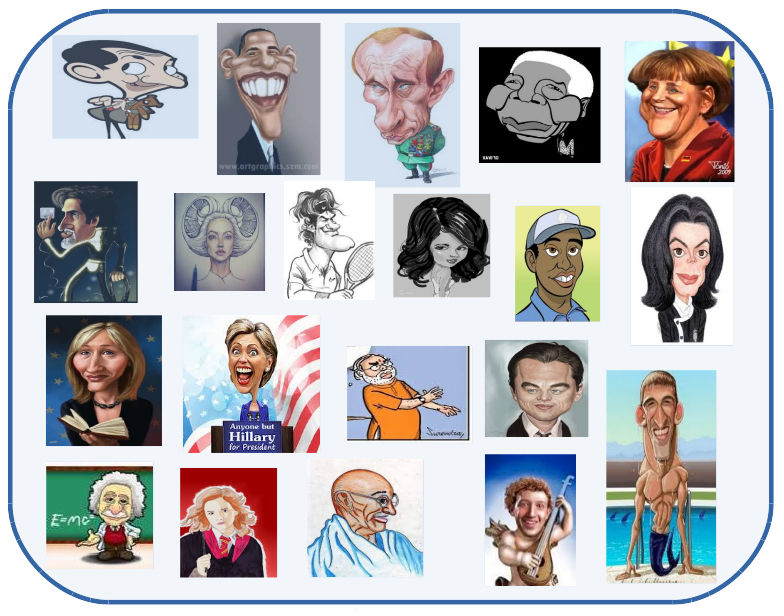
The IIIT-CFW is database for the cartoon faces in the wild. It is harvested from Google image search. Query words such as Obama + cartoon, Modi + cartoon, and so on were used to collect cartoon images of 100 public figures. The dataset contains 8928 annotated cartoon faces of famous personalities of the world with varying profession. Additionally, we also provide 1000 real faces of the public figure to study cross modal retrieval tasks, such as, Photo2Cartoon retrieval. The IIIT-CFW can be used for the study spectrum of problems as discussed in our paper.
Keywords: Cartoon faces, face synthesis, sketches, heterogeneous face recognition, cross modal retrieval, caricature.
Downloads
IIIT-CFW (133.5 MB)
Usage:
Task 1 -- cartoon face classification
Task 2 -- Photo2Cartoon
README
Older version:
IIIT-CFW (85 MB)
Related Publications
Ashutosh Mishra, Shyam Nandan Rai, Anand Mishra and C. V. Jawahar, IIIT-CFW: A Benchmark Database of Cartoon Faces in the Wild, 1st workshop on visual analysis and sketch (ECCVW) 2016. [PDF]
Bibtex
If you use this dataset, please cite:
@InProceedings{MishraECCV16,
author = "Mishra, A., Nandan Rai, S., Mishra, A. and Jawahar, C.~V.",
title = "IIIT-CFW: A Benchmark Database of Cartoon Faces in the Wild",
booktitle = "VASE ECCVW",
year = "2016",
}
Contact
For any queries about the dataset feel free to contact Anand Mishra. Email: