TBD
IndicSTR12: A Dataset for Indic Scene Text Recognition
, ,
[Paper] [Code] [Synthetic Dataset] [Real Dataset] [Poster]
ICDAR , 2023
Abstract

We present a comprehensive dataset comprising 12 major Indian languages, including Assamese, Bengali, Odia, Marathi, Hindi, Kannada, Urdu, Telugu, Malayalam, Tamil, Gujarati, and Punjabi. The dataset consists of real word images, with a minimum of 1000 images per language, accompanied by their corresponding labels in Unicode. This dataset can serve various purposes such as script identification, scene text detection, and recognition.
We employed a web crawling approach to assemble this dataset, specifically gathering images from Google Images through targeted keyword-based searches. Our methodology ensured coverage of diverse everyday scenarios where Indic language text is commonly encountered. Examples include wall paintings, railway stations, signboards, nameplates of shops, temples, mosques, and gurudwaras, advertisements, banners, political protests, and house plates. Since the images were sourced from a search engine, they originate from various contexts, providing various conditions under which the images were captured.
The curated dataset encompasses images with different characteristics, such as blurriness, non-iconic or iconic text, low resolution, occlusions, curved text, and perspective projections resulting from non-frontal viewpoints. This diversity in image attributes adds to the dataset's realism and utility for various research and application domains
Additionally, we introduce a synthetic dataset specifically designed for 13 Indian languages (including Manipuri - Meitei Script). This dataset aims to advance the field of Scene Text Recognition (STR) by enabling research and development in the area of multi-lingual STR. In essence, this synthetic dataset serves a similar purpose as the well-known SynthText and MJSynth datasets, providing valuable resources for training and evaluating text recognition models.
Benchmarking Approach
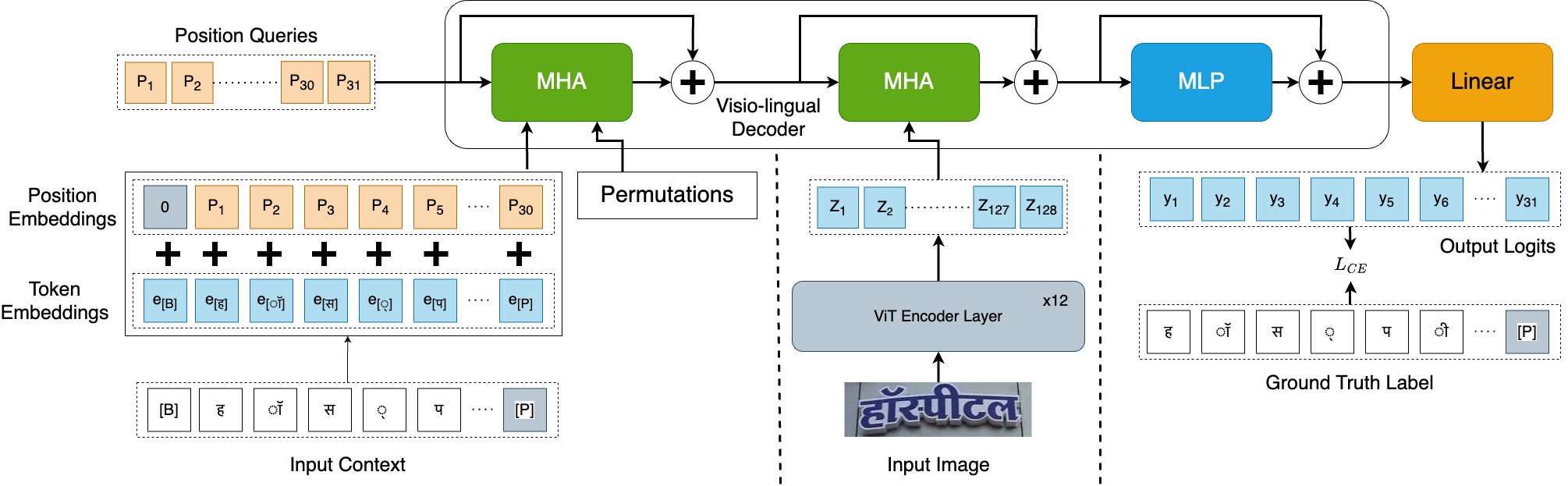
For the IndicSTR12 dataset, three models were selected for benchmarking the performance of Scene Text Recognition (STR) on 12 Indian languages. These models are as follows:
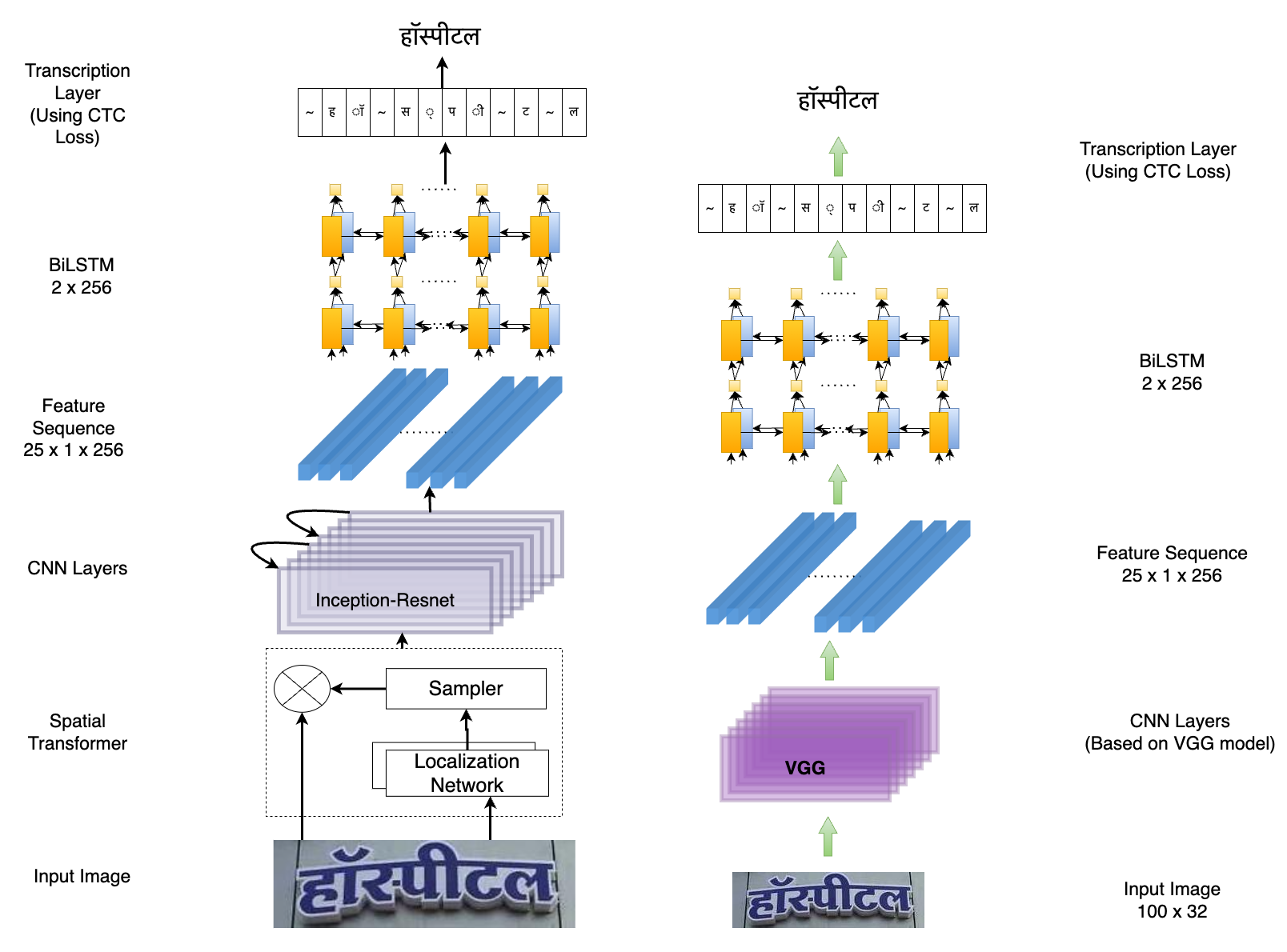
PARSeq: This model is the current state-of-the-art for Latin STR and it achieves high accuracy.
CRNN: Despite having lower accuracy compared to many current models, CRNN is widely adopted by the STR community for practical purposes due to its lightweight nature and fast processing speed.
STARNet: This model excels at extracting robust features from word-images and includes an initial distortion correction step on top of CRNN architecture. It has been chosen for benchmarking to maintain consistency with previous research on Indic STR.
These three models were specifically chosen to evaluate and compare their performance on the IndicSTR12 dataset, enabling researchers to assess the effectiveness of various STR approaches on the Indian languages included in the dataset.
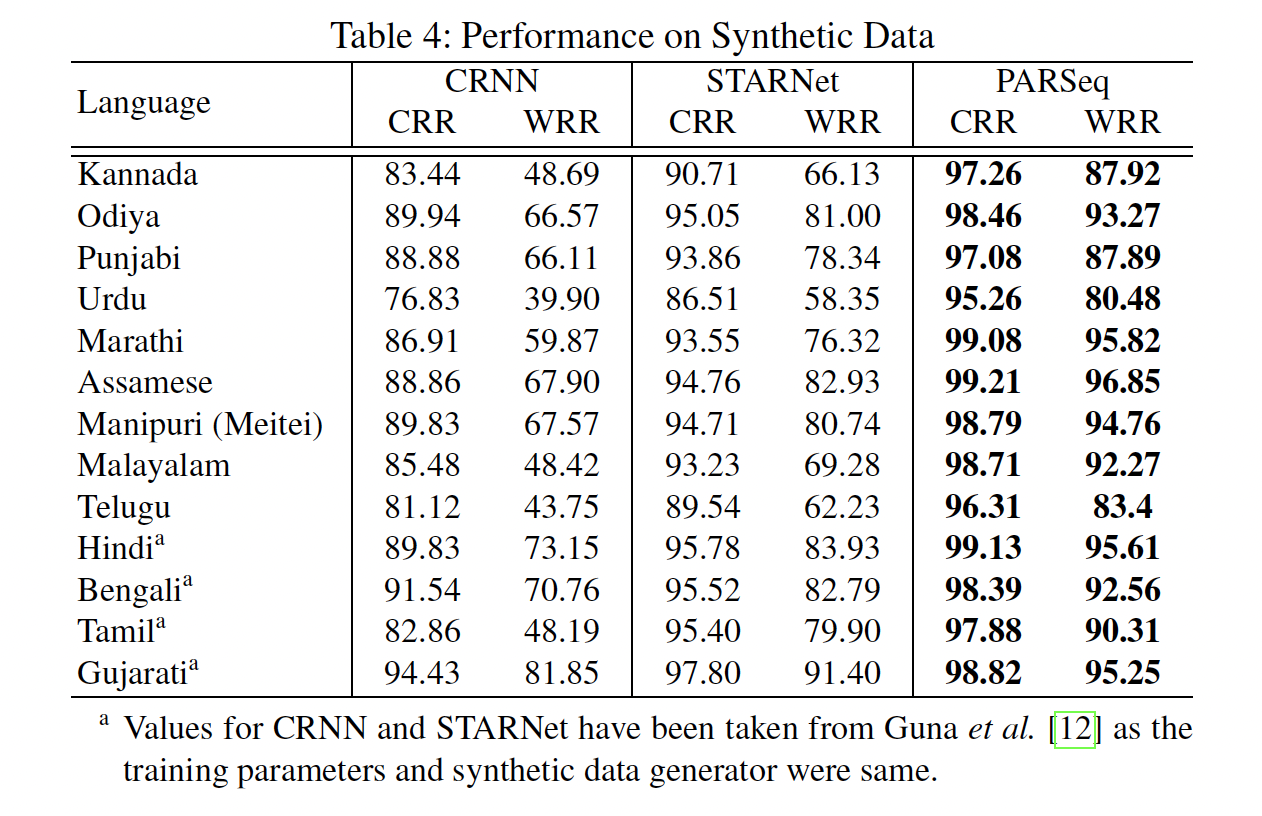
Result
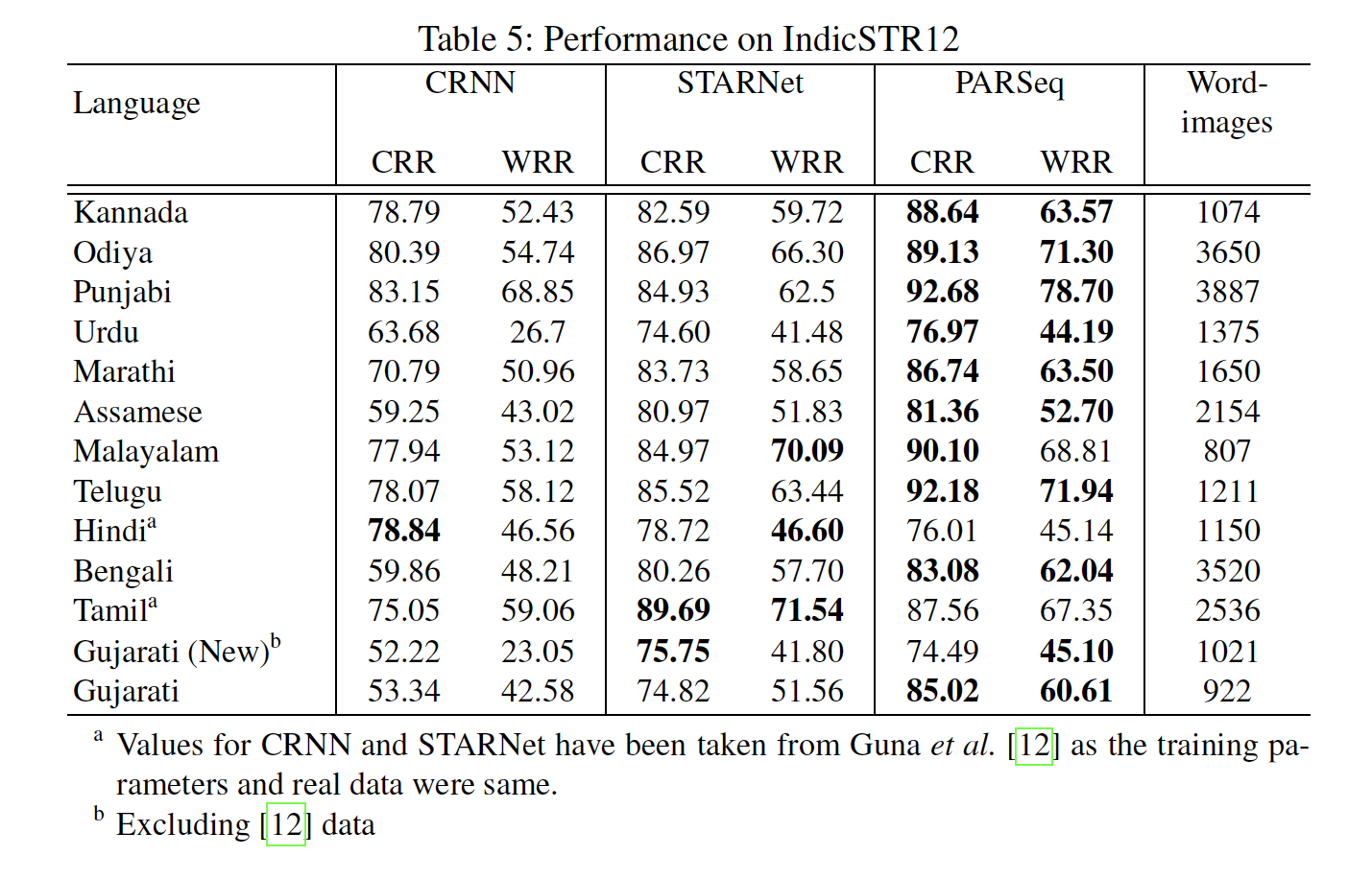
Dataset


Citation
@inproceedings{lunia2023indicstr12,
title={IndicSTR12: A Dataset for Indic Scene Text Recognition},
author={Lunia, Harsh and Mondal, Ajoy and Jawahar, CV},
booktitle={International Conference on Document Analysis and Recognition},
pages={233--250},
year={2023},
organization={Springer}
}
Acknowledgements
This work is supported by MeitY, Government of India, through the NLTM-Bhashini project.
Reading Between the Lanes: Text VideoQA on the Road
, , , ,
ICDAR, 2023
[ Paper ] [ Dataset ]

Abstract
Text and signs around roads provide crucial information for drivers, vital for safe navigation and situational awareness. Scene text recognition in motion is a challenging problem, while textual cues typically appear for a short time span, and early detection at a distance is necessary. Systems that exploit such information to assist the driver should not only extract and incorporate visual and textual cues from the video stream but also reason over time. To address this issue, we introduce RoadTextVQA, a new dataset for the task of video question answering (VideoQA) in the context of driver assistance. RoadTextVQA consists of 3,222 driving videos collected from multiple countries, annotated with 10,500 questions, all based on text or road signs present in the driving videos. We assess the performance of state-of-the-art video question answering models on our RoadTextVQA dataset, highlighting the significant potential for improvement in this domain and the usefulness of the dataset in advancing research on in-vehicle support systems and text-aware multimodal question answering.
Contact
Towards MOOCs for Lipreading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale
* indicates equal contribution
[Paper] [Video]
Abstract
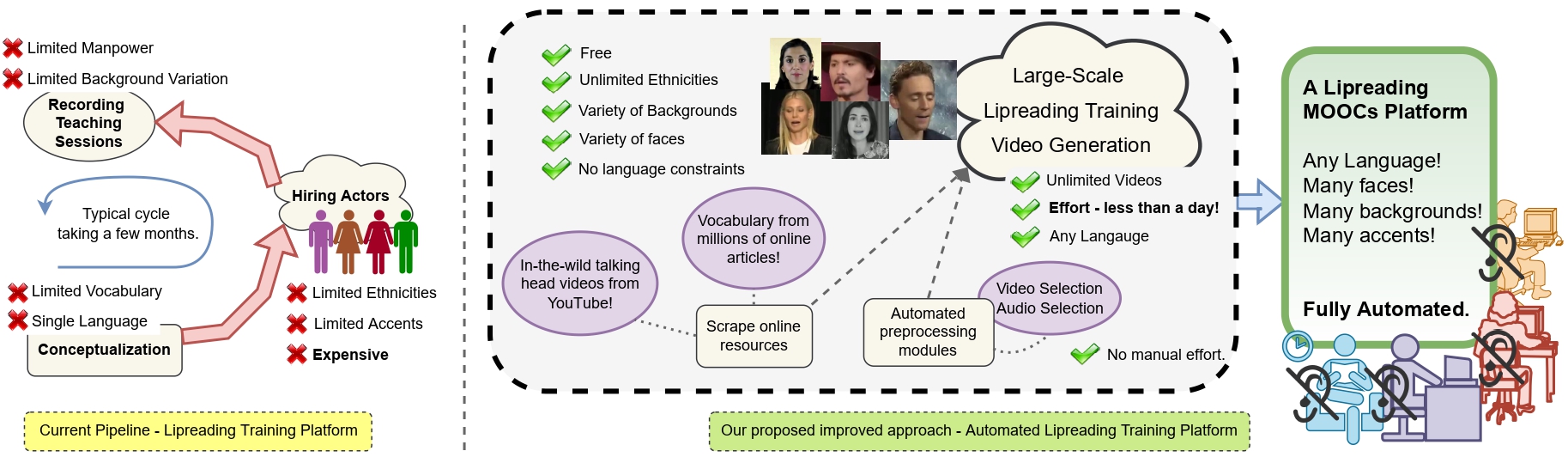
Many people with some form of hearing loss consider lipreading as their primary mode of day-to-day communication. However, finding resources to learn or improve one's lipreading skills can be challenging. This is further exacerbated in the COVID19 pandemic due to restrictions on direct interactions with peers and speech therapists. Today, online MOOCs platforms like Coursera and Udemy have become the most effective form of training for many types of skill development. However, online lipreading resources are scarce as creating such resources is an extensive process needing months of manual effort to record hired actors. Because of the manual pipeline, such platforms are also limited in vocabulary, supported languages, accents, and speakers and have a high usage cost. In this work, we investigate the possibility of replacing real human talking videos with synthetically generated videos. Synthetic data can easily incorporate larger vocabularies, variations in accent, and even local languages and many speakers. We propose an end-to-end automated pipeline to develop such a platform using state-of-the-art talking head video generator networks, text-to-speech models, and computer vision techniques. We then perform an extensive human evaluation using carefully thought out lipreading xercises to validate the quality of our designed platform against the existing lipreading platforms. Our studies concretely point toward the potential of our approach in developing a large-scale lipreading MOOC platform that can impact millions of people with hearing loss.
Overview
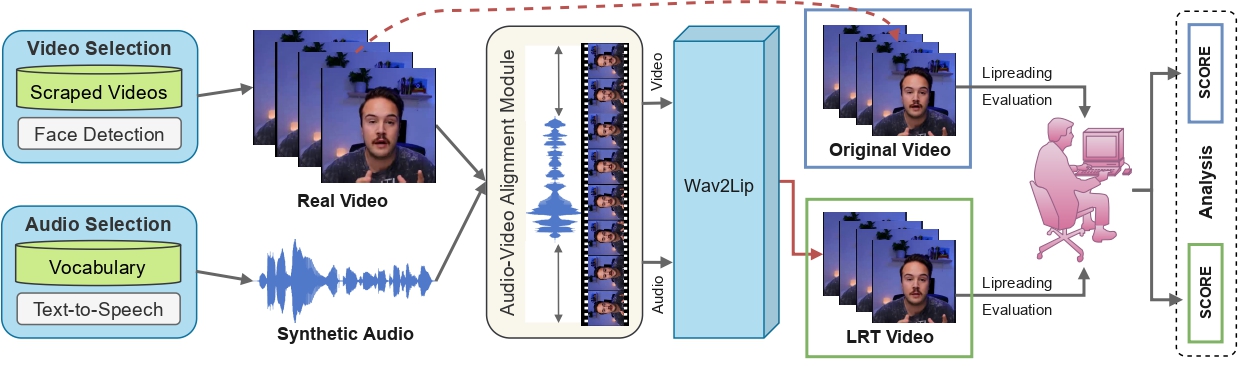
Lipreading is a primary mode of communication for people with hearing loss. However, learning to lipread is not an easy task! Lipreading can be thought of being analogous to "learning a new language" for people without hearing disabilities. People needing this skill undergo formal education in special schools and involve medically trained speech therapists. Other resources like daily interactions also help understand and decipher language solely from lip movements. However, these resources are highly constrained and inadequate for many patients suffering from hearing disabilities. We envision a MOOCs platform for LipReading Training (LRT) for the hearing disabled. We propose a novel approach to automatically generate a large-scale database for developing an LRT MOOCs platform. We use SOTA text-to-speech (TTS) models and talking head generators like Wav2Lip to generate training examples automatically. Wav2Lip requires driving face videos and driving speech segments (generated from TTS in our case) to generate lip-synced talking head videos according to driving speech. It preserves the head pose, background, identity, and distance of the person from the camera while modifying only the lip movements. Our approach can exponentially increase the amount of online content on the LRT platforms in an automated and cost-effective manner. It can also seamlessly increase the vocabulary and the number of speakers in the database.
Test Design
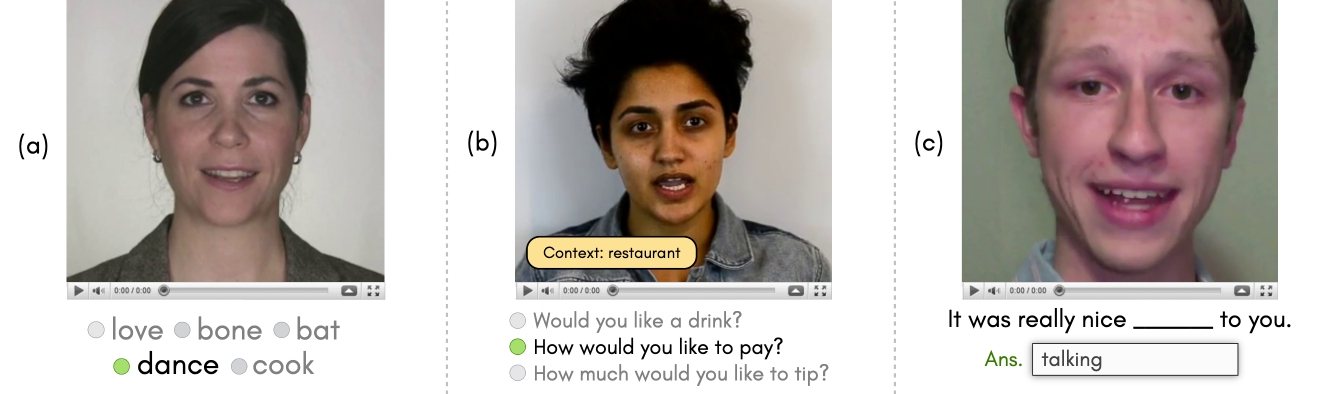
Lipreading is an involved process of recognizing speech from visual cues - the shape formed by the lips, teeth, and tongue. A lipreader may also rely on several other factors, such as the context of the conversation, familiarity with the speaker, vocabulary, and accent. Thus, taking inspiration from lipreading.org and readourlips.ca, we define three lipreading protocols for conducting a user study to evaluate the viability of our platform - (1) lipreading on isolated words (WL), (2) lipreading sentences with context (SL), and (3) lipreading missing words in sentences (MWIS). These protocols rely on a lipreader's vocabulary and the role that semantic context plays in a person's ability to lipread. In word-level (WL) lipreading, the user is presented with a video of an isolated word being spoken by a talking head, along with multiple choices and one correct answer. When a video is played on the screen, the user must respond by selecting a single response from the provided multiple choices. Visually similar words (homophenes) are placed as options in the multiple choices to increase the difficulty of the task. The difficulty can be further increased by testing for difficult words - difficulty associated with the word to lipread. In sentence-level (SL) lipreading, the users are presented with (1) videos of talking heads speaking entire sentences and (2) the context of the sentences. The context acts as an additional cue to the mouthing of sentences and is meant to simulate practical conversations in a given context. In lipreading missing words in sentences (MWIS), the participants watch videos of sentences spoken by a talking head with a word in the sentence masked. Unlike SL, the users are not provided with any additional sentence context. Lip movements are an ambiguous source of information due to the presence of homophenes. This exercise thus aims to use the context of the sentence to disambiguate between multiple possibilities and guess the correct answer.
User Study
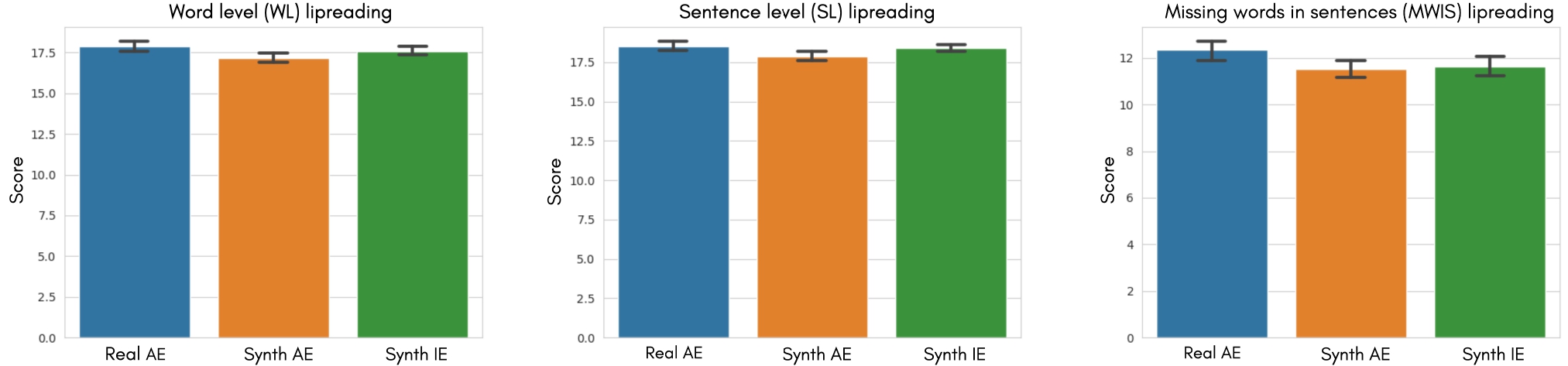
We conduct statistical analysis to verify (T1) If the lipreading performance of the users remains comparable across the real and synthetic videos generated using our pipeline. Through this, we will validate the viability of our proposed pipeline as an alternative to the existing online lipreading training platforms. (T2) If the users are more comfortable lipreading in their native accent/language than in a foreign accent/language. This would validate the need for bootstrapping lipreading training platforms in multiple languages/accents across the globe. The mean user performance on the three lipreading protocols are shown as standard errors of the mean.
Citation
@misc{agarwal2023lrt,
doi = {10.48550/ARXIV.2208.09796},
url = {https://arxiv.org/abs/2208.09796},
author = {Agarwal, Aditya and Sen, Bipasha and Mukhopadhyay, Rudrabha and Namboodiri, Vinay and Jawahar, C. V.},
keywords = {Computer Vision and Pattern Recognition (cs.CV)},
title = {Towards MOOCs for Lipreading: Using Synthetic Talking Heads to Train Humans in Lipreading at Scale},
publisher = {IEEE/CVF Winter Conference on Applications of Computer Vision},
year = {2023},
}
FaceOff: A Video-to-Video Face Swapping System
* indicates equal contribution
[Paper] [Video] [Code]
Abstract
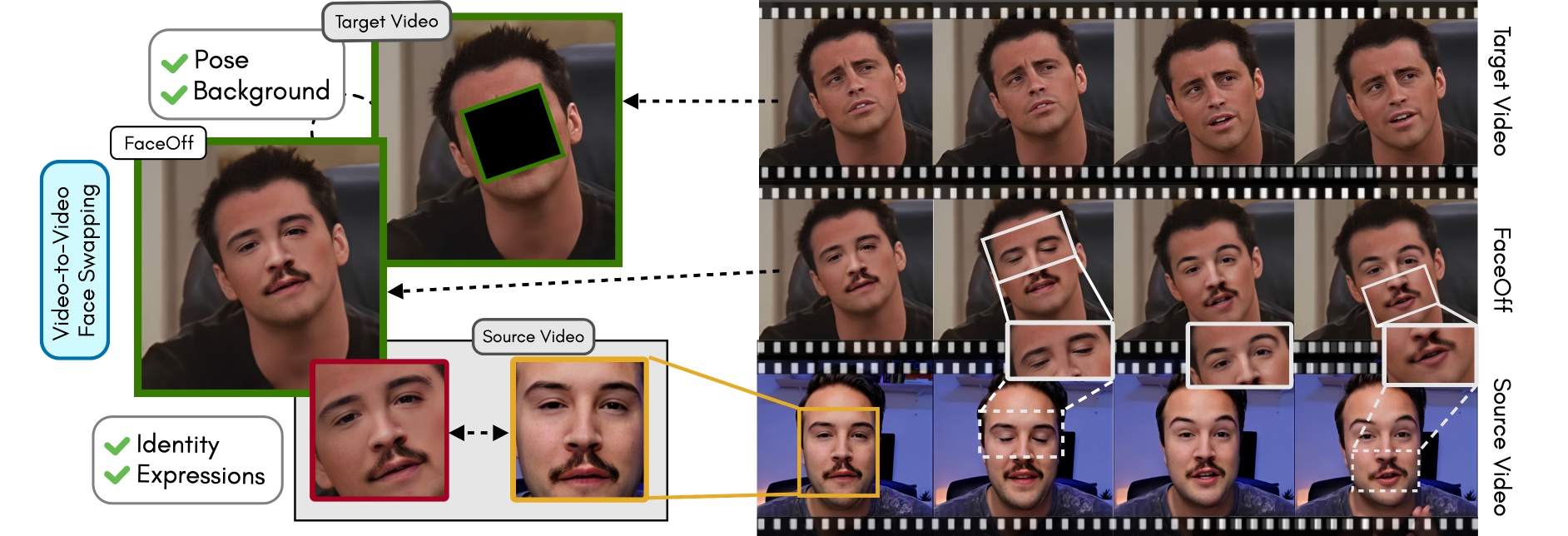
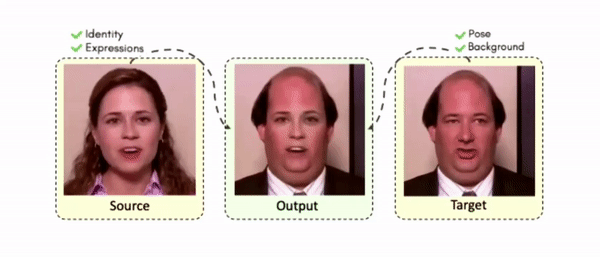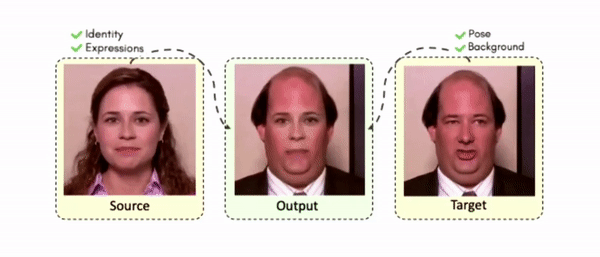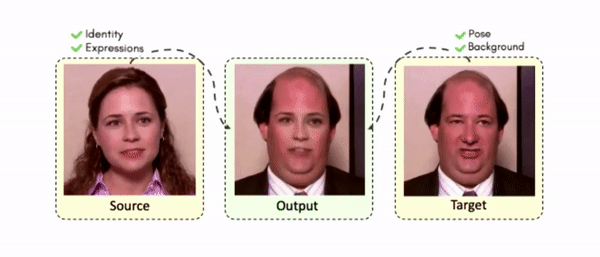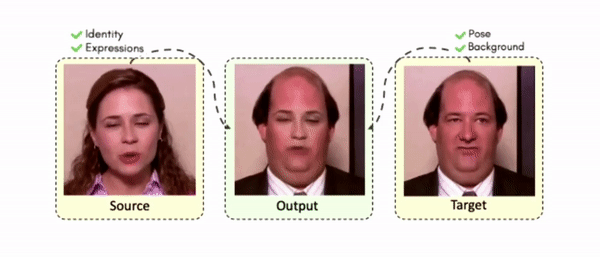
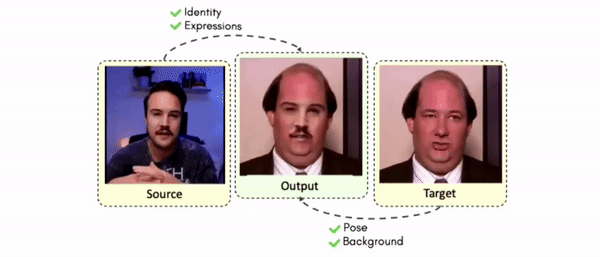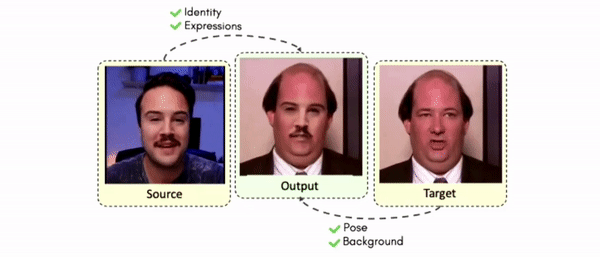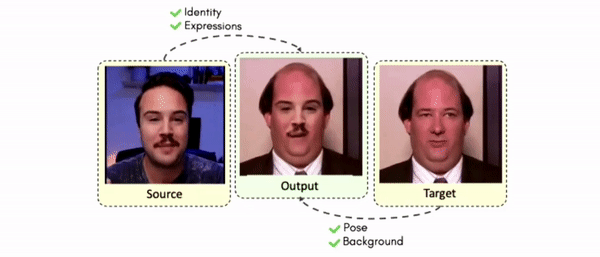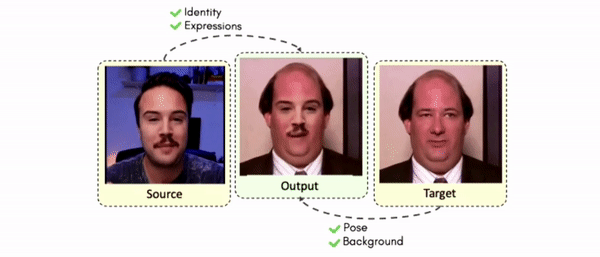
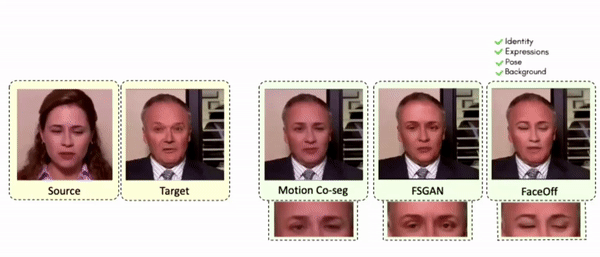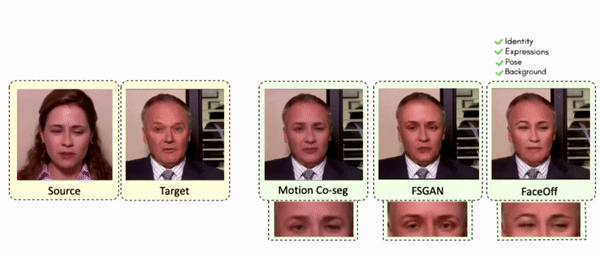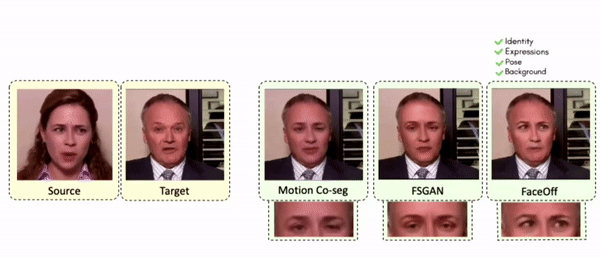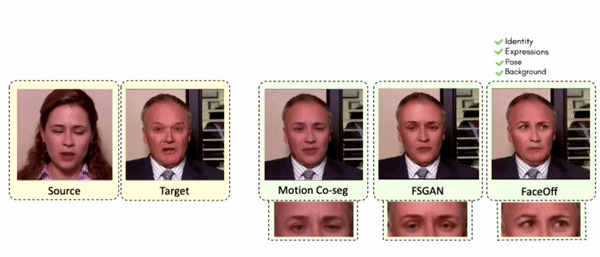
Doubles play an indispensable role in the movie industry. They take the place of the actors in dangerous stunt scenes or scenes where the same actor plays multiple characters. The double's face is later replaced with the actor's face and expressions manually using expensive CGI technology, costing millions of dollars and taking months to complete. An automated, inexpensive, and fast way can be to use face-swapping techniques that aim to swap an identity from a source face video (or an image) to a target face video. However, such methods cannot preserve the source expressions of the actor important for the scene's context. To tackle this challenge, we introduce video-to-video (V2V) face-swapping, a novel task of face-swapping that can preserve (1) the identity and expressions of the source (actor) face video and (2) the background and pose of the target (double) video. We propose FaceOff, a V2V face-swapping system that operates by learning a robust blending operation to merge two face videos following the constraints above. It reduces the videos to a quantized latent space and then blends them in the reduced space. FaceOff is trained in a self-supervised manner and robustly tackles the non-trivial challenges of V2V face-swapping. As shown in the experimental section, FaceOff significantly outperforms alternate approaches qualitatively and quantitatively.
Overview
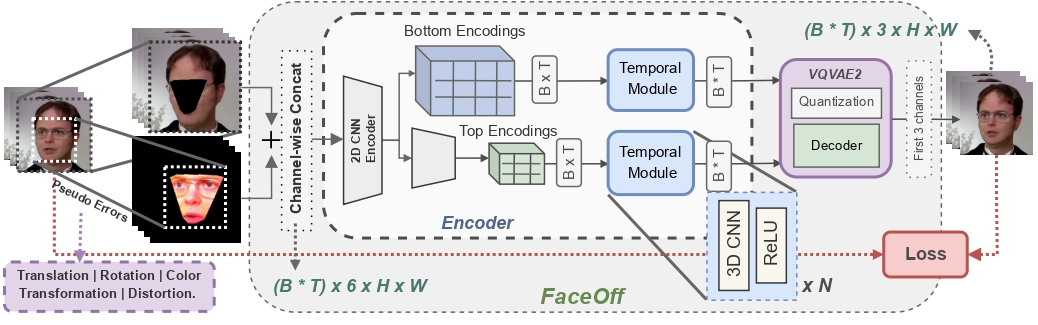
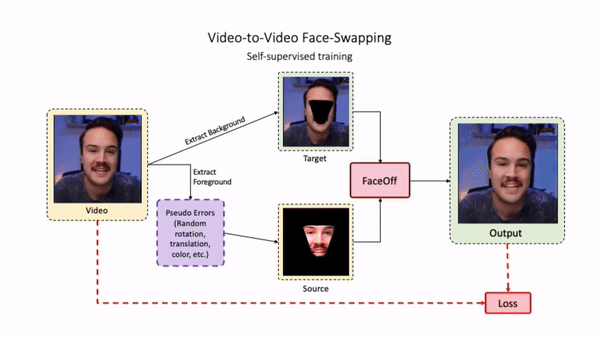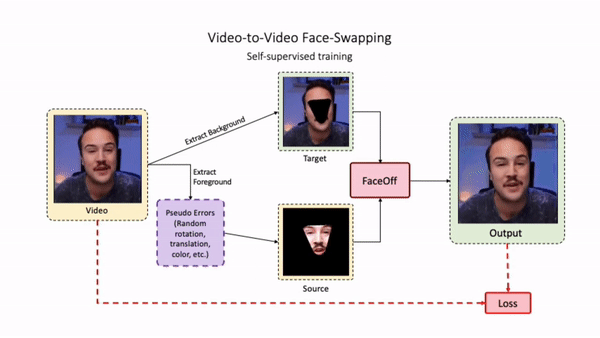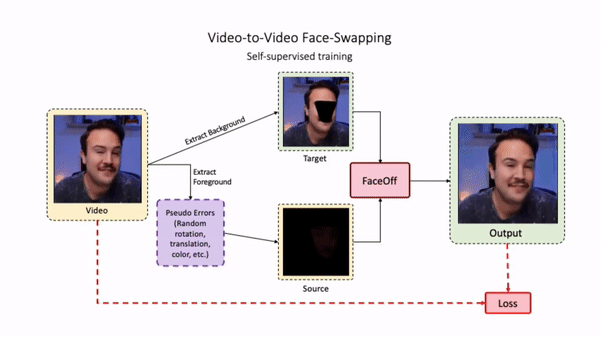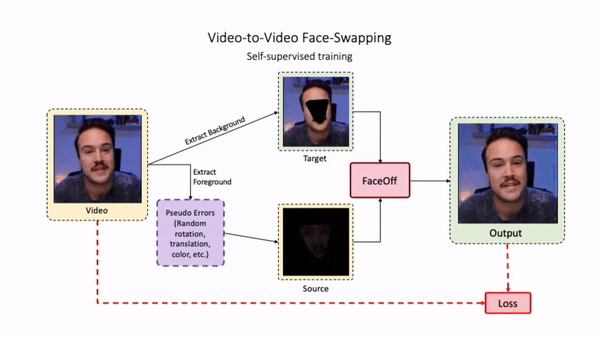
Swapping faces across videos is non-trivial as it involves merging two different motions - the actor's face motion and the double's head motion. This needs a network that can take two different motions as input and produce a third coherent motion. FaceOff is a video-to-video face swapping system that reduces the face videos to a quantized latent space and blends them in the reduced space. A fundamental challenge in training such a network is the absence of ground truth. FaceOff uses a self-supervised training strategy for training: A single video is used as the source and target. We then introduce pseudo motion errors on the source video. Finally, we train a network to fix these pseudo errors to regenerate the source video. To do this, we learn to blend the foreground of the source video with the background and pose of the target face video such that the blended output is coherent and meaningful. We use a temporal autoencoding module that merges the motion of the source and the target video using a quantized latent space. We propose a modified vector quantized encoder with temporal modules made of non-linear 3D convolution operations to encode the video to the quantized latent space. The input to the encoder is a single video made by concatenating the source foreground and target background frames channel-wise. The encoder first encodes the concatenated video input framewise into 32x32 and 64x64 dimensional top and bottom hierarchies, respectively. Before the quantization step at each of the hierarchies, the temporal modules process the reduced video frames. This step allows the network to backpropagate with temporal connections between the frames. The decoder then decodes the reduced frames using a distance loss with the ground truth video as supervision. The output is a temporally and spatially coherent blended video of the source foreground and the target background.
FaceOff Video-to-Video Face Swapping
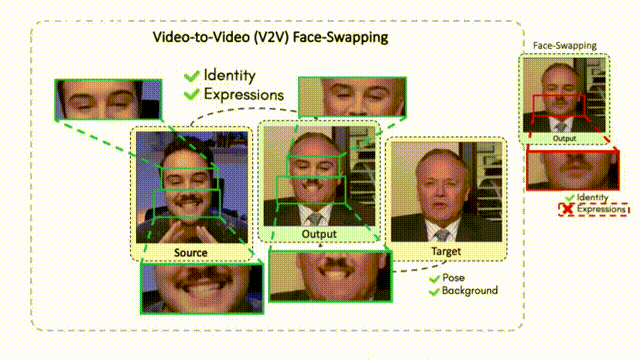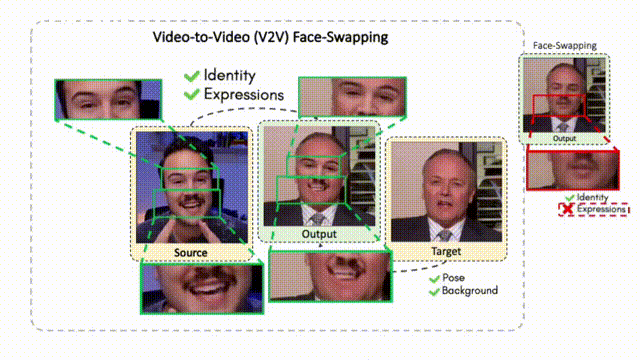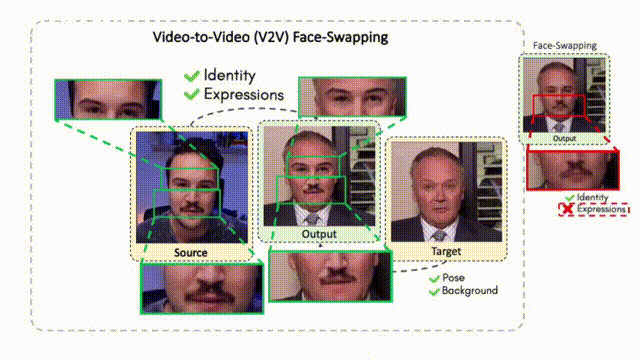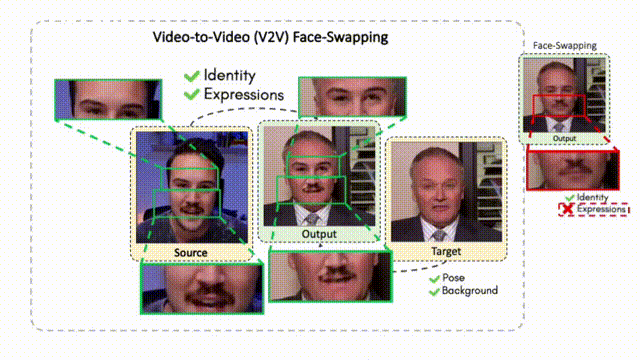

Training Pipeline
Inference Pipeline
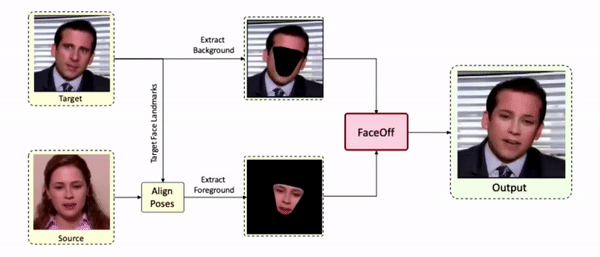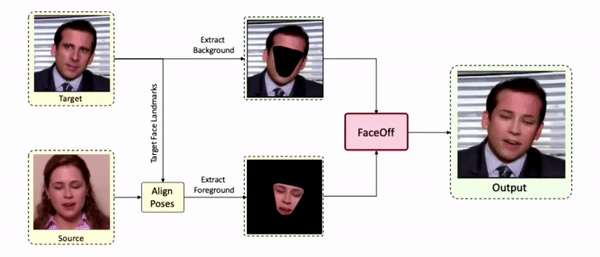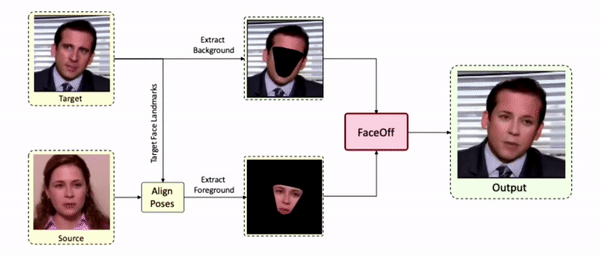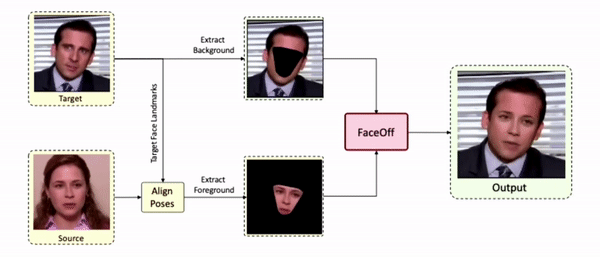
Results on Unseen Identities


Comparisons


Results on Same Identity
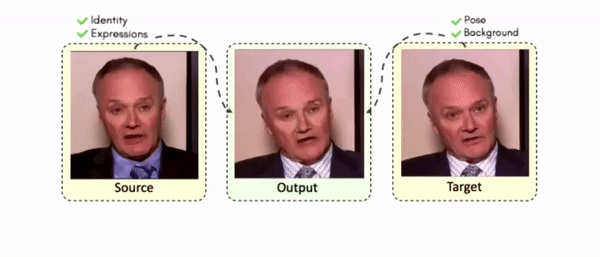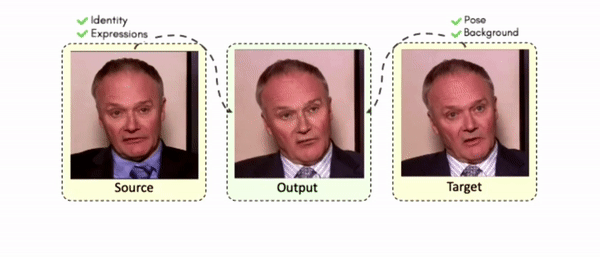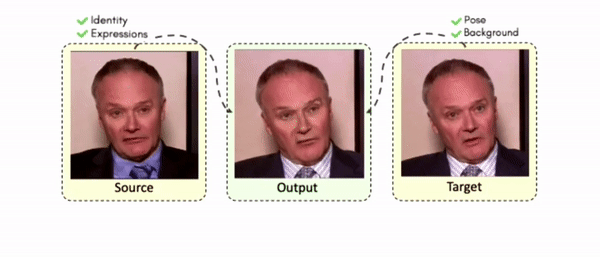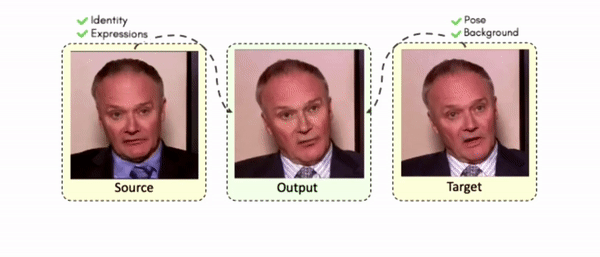
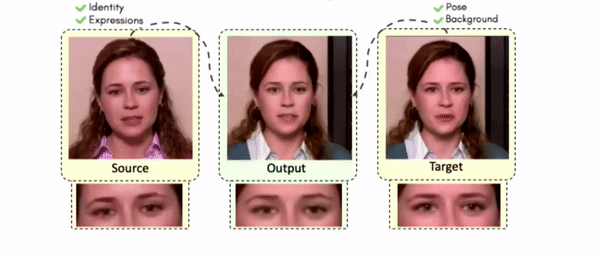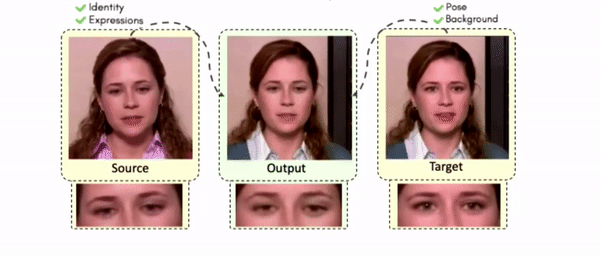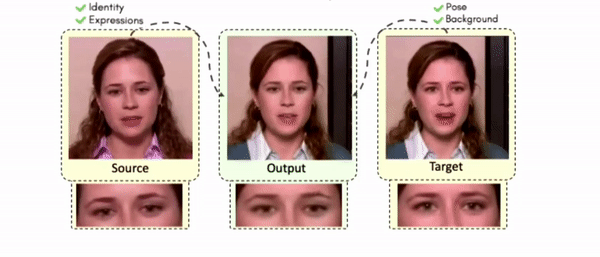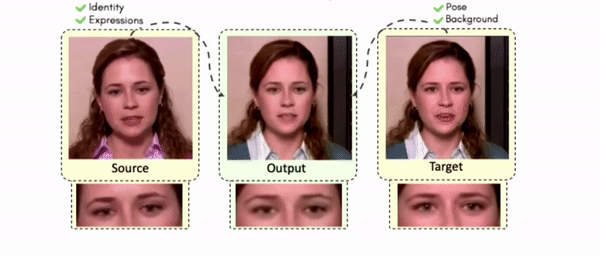

Some More Results

Citation
@misc{agarwal2023faceoff,
doi = {10.48550/ARXIV.2208.09788},
url = {https://arxiv.org/abs/2208.09788},
author = {Agarwal, Aditya and Sen, Bipasha and Mukhopadhyay, Rudrabha and Namboodiri, Vinay and Jawahar, C. V.},
keywords = {Computer Vision and Pattern Recognition (cs.CV)},
title = {FaceOff: A Video-to-Video Face Swapping System},
publisher = {IEEE/CVF Winter Conference on Applications of Computer Vision},
year = {2023},
}