Handwritten Text Retrieval from Unlabeled Collections
Santhoshini Gongidi and C.V. Jawahar
[ Paper ] | [ Demo ]
Abstract
Handwritten documents from communities like cultural heritage, judiciary, and modern journals remain largely unexplored even today. To a great extent, this is due to the lack of retrieval tools for such unlabeled document collections. In this work, we consider such collections and present a simple, robust retrieval framework for easy information access. We achieve retrieval on unlabeled novel collections through invariant features learnt for handwritten text. These feature representations enable zero-shot retrieval for novel queries on unexplored collections. We improve the framework further by supporting search via text and exemplar queries. Four new collections written in English, Malayalam, and Bengali are used to evaluate our text retrieval framework. These collections comprise 2957 handwritten pages and over 300K words. We report promising results on these collections, despite the zero-shot constraint and huge collection size. Our framework allows the addition of new collections without any need for specific finetuning or labeling. Finally, we also present a demonstration of the retrieval framework.
Demo link: HW-Search
Teaser Video:
Related Publications
Santhoshini Gongidi, C V Jawahar, Handwritten Text Retrieval from Unlabeled Collections, CVIP 2021
Contact
For any queries about the work, please contact the authors below
- Santhoshini Gongidi:
This email address is being protected from spambots. You need JavaScript enabled to view it.

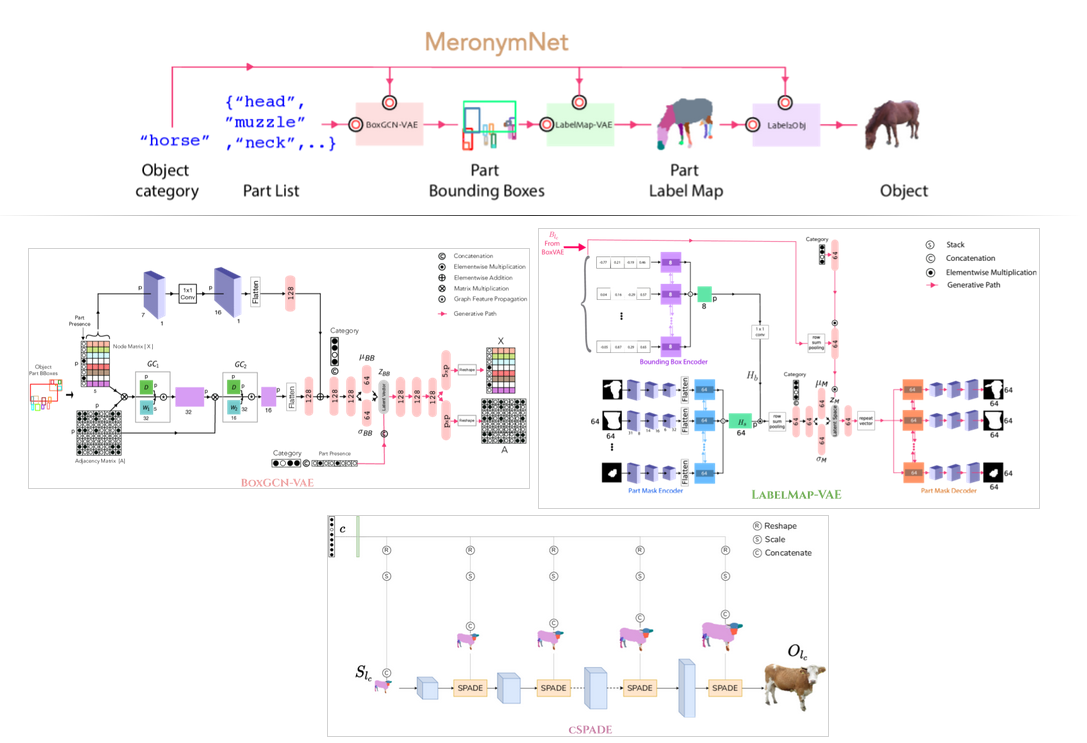
 Look at sample generations by MeronymNet. For each sample, the generated bounding box, corresponding label mask and the RGB object can be seen. Notice the diversity in number of parts, appearance and viewpoint among the generated objects.
Look at sample generations by MeronymNet. For each sample, the generated bounding box, corresponding label mask and the RGB object can be seen. Notice the diversity in number of parts, appearance and viewpoint among the generated objects.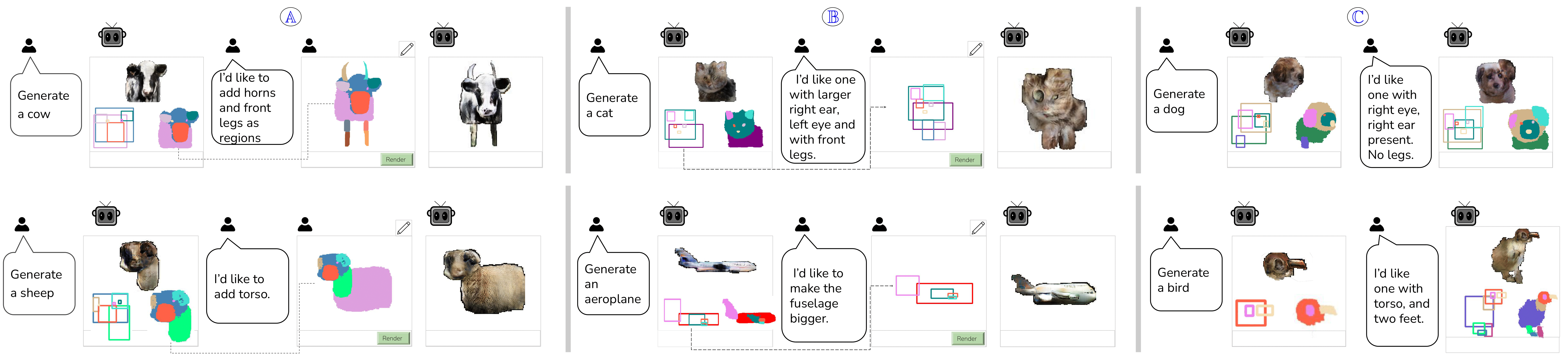 Our model allows users to have control on part level, which they can interact with either using boxes or masks. Notice that the viewpoint for rendering the object has changed from the initial generation to accommodate the updated part list. This scenario especially demonstrates MeronymNet’s holistic, part-based awareness of rendering viewpoints best suited for various part sets.
Our model allows users to have control on part level, which they can interact with either using boxes or masks. Notice that the viewpoint for rendering the object has changed from the initial generation to accommodate the updated part list. This scenario especially demonstrates MeronymNet’s holistic, part-based awareness of rendering viewpoints best suited for various part sets.  We use the large-scale part-segmented object dataset, PASCAL Parts. The plot shows the density distribution of part counts in object instances for each category. The varying range and frequency of part occurrences across categories, combined with the requirement of object generation from a single unified model, poses lots of challenges.
We use the large-scale part-segmented object dataset, PASCAL Parts. The plot shows the density distribution of part counts in object instances for each category. The varying range and frequency of part occurrences across categories, combined with the requirement of object generation from a single unified model, poses lots of challenges. 