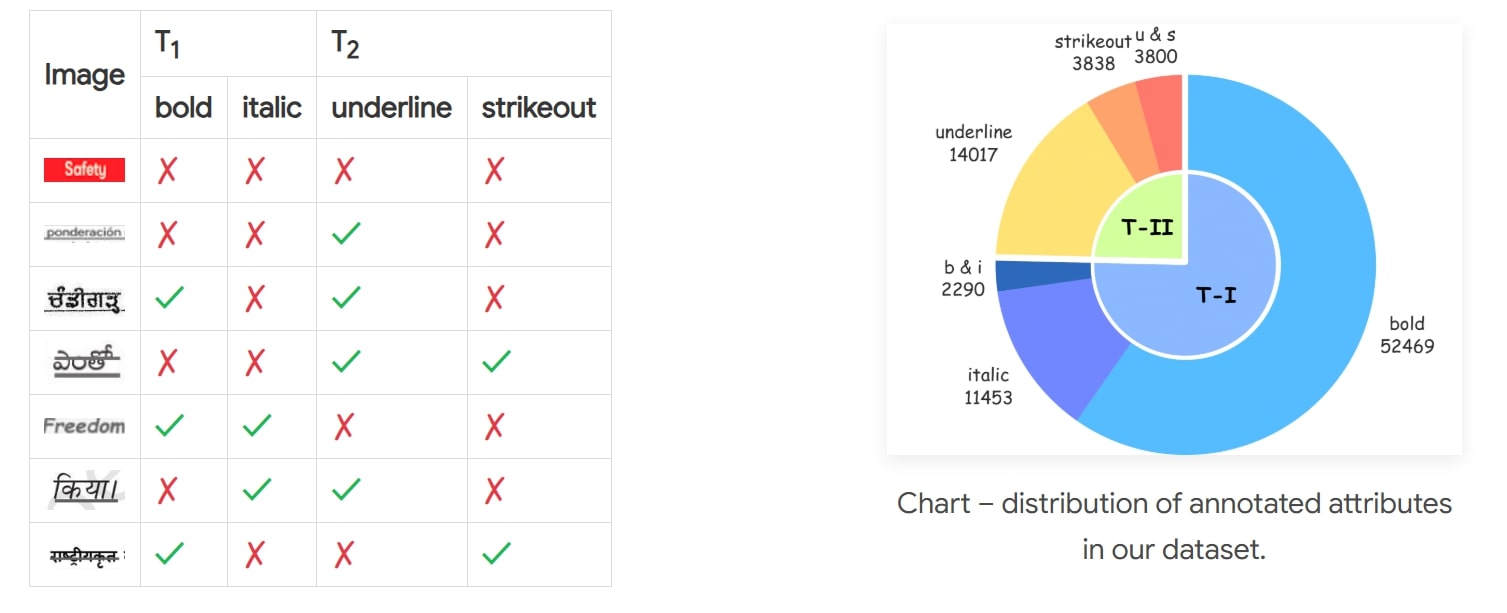
PedestrianQA : A Benchmark for Vision-Language Models on Pedestrian Intention and Trajectory Prediction
[Paper] [Dataset] [Project Page]
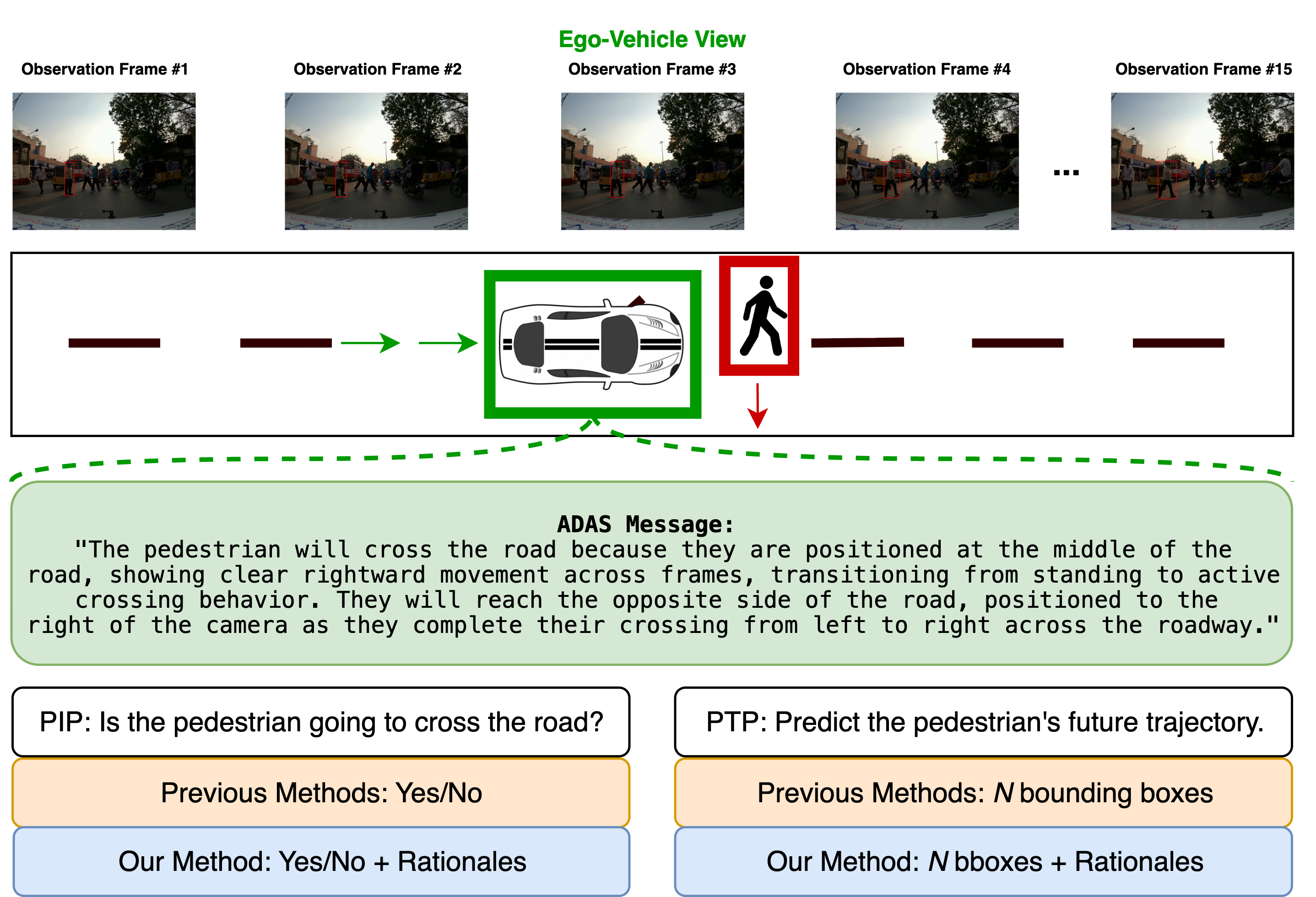
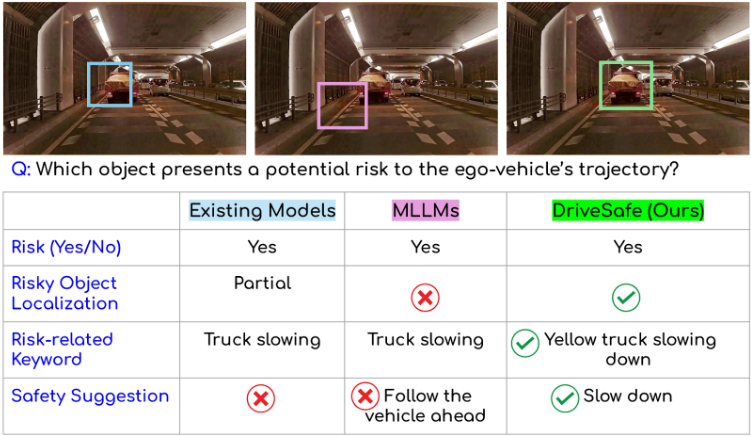
Fig: An illustration of an unstructured-traffic scenario where a pedestrian stands in the middle of the road in front of the ego-vehicle, attempting to cross the road. Unlike prior approaches that provide only predictions, our method predicts the intention and trajectory and generates supporting rationales.
Abstract
Pedestrian intention and trajectory prediction are critical for the safe deployment of autonomous driving systems, directly influencing navigation decisions in complex traffic environments. Recent advances in large vision–language models offer a powerful new paradigm for these tasks by combining high-capacity visual understanding with flexible natural lan- guage reasoning. In this work, we introduce PedestrianQA, a large-scale video-based dataset that formulates pedestrian intention and trajectory prediction as a question–answering tasks augmented with structured rationales. PedestrianQA expresses richly annotated pedestrian sequences, in natural language, enabling VLMs to learn from visual dynamics, contextual cues, and interactions among traffic agents while generating concise explanations of their predictions without needing specialized architectures tailored for each task. Empirical evaluations across PIE, JAAD, TITAN, and IDD-PeD show that finetuning state-of-the-art VLMs on PedestrianQA significantly improves intention classification, trajectory forecasting accuracy, and the quality of explanatory rationales, demonstrating the strong potential of VLMs as a unified and explainable framework for safety-critical pedestrian behavior modeling. The dataset and model will be made publicly available.
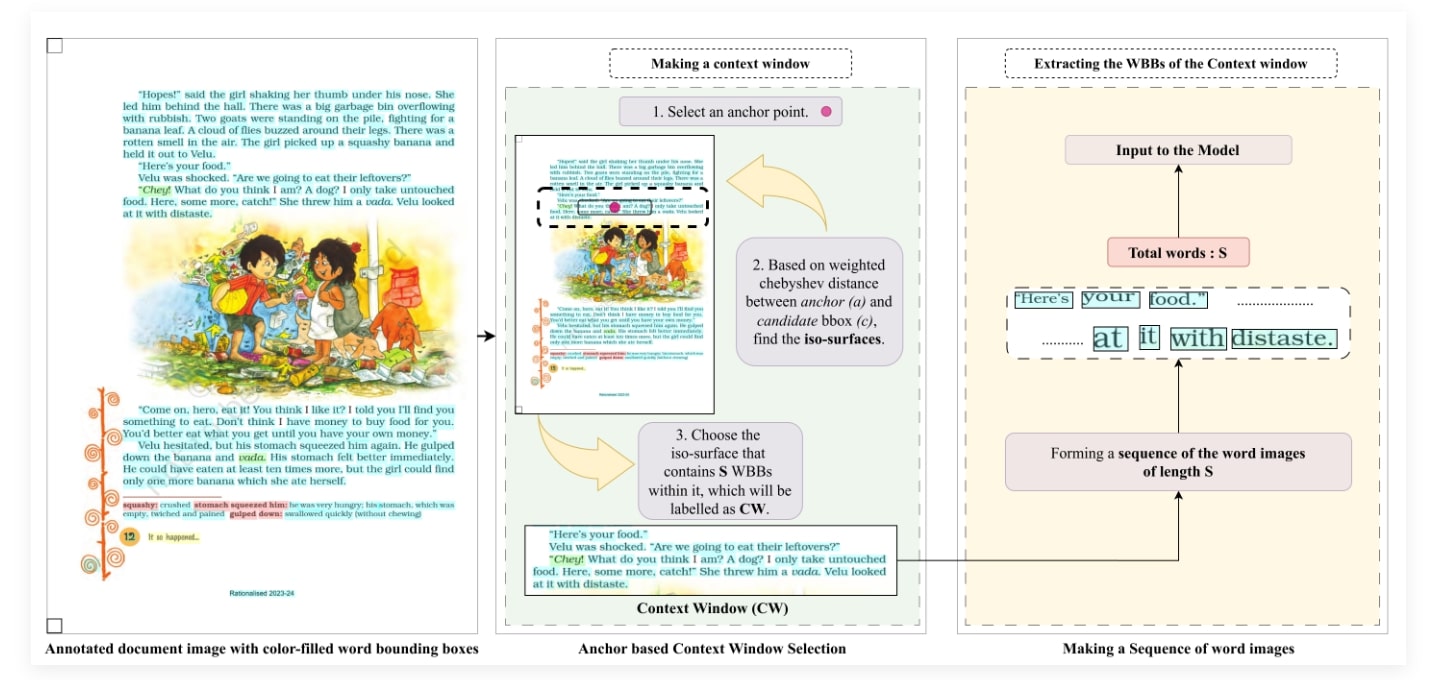
PedestrianQA Dataset

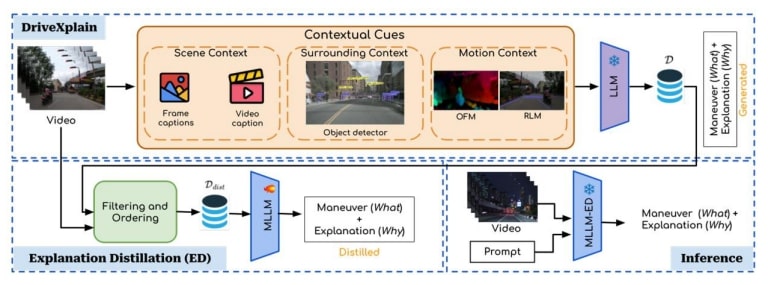
Fig:Data generation pipeline: We first aggregate all ground-truth, human-annotated annotations from the constituent datasets into a unified metadata schema. We use generated VLM captions to enrich motion semantics using carefully designed pedestrian-motion prompts that target fine-grained cues. These captions are validated for format and appended to the metadata. We then construct a single instruction package containing: (i) a system prompt, (ii) task definitions for PIP and PTP, (iii) step-by-step guidance for producing structured, fine-grained rationales, (iv) a small set of in-context exemplars, (v) a compliance checklist for high-quality rationale generation, and (vi) the sequence-level metadata tables. This package is provided to claude-sonnet-4-20250514 LLM-API to generate triplets of questions, answers, and rationales.
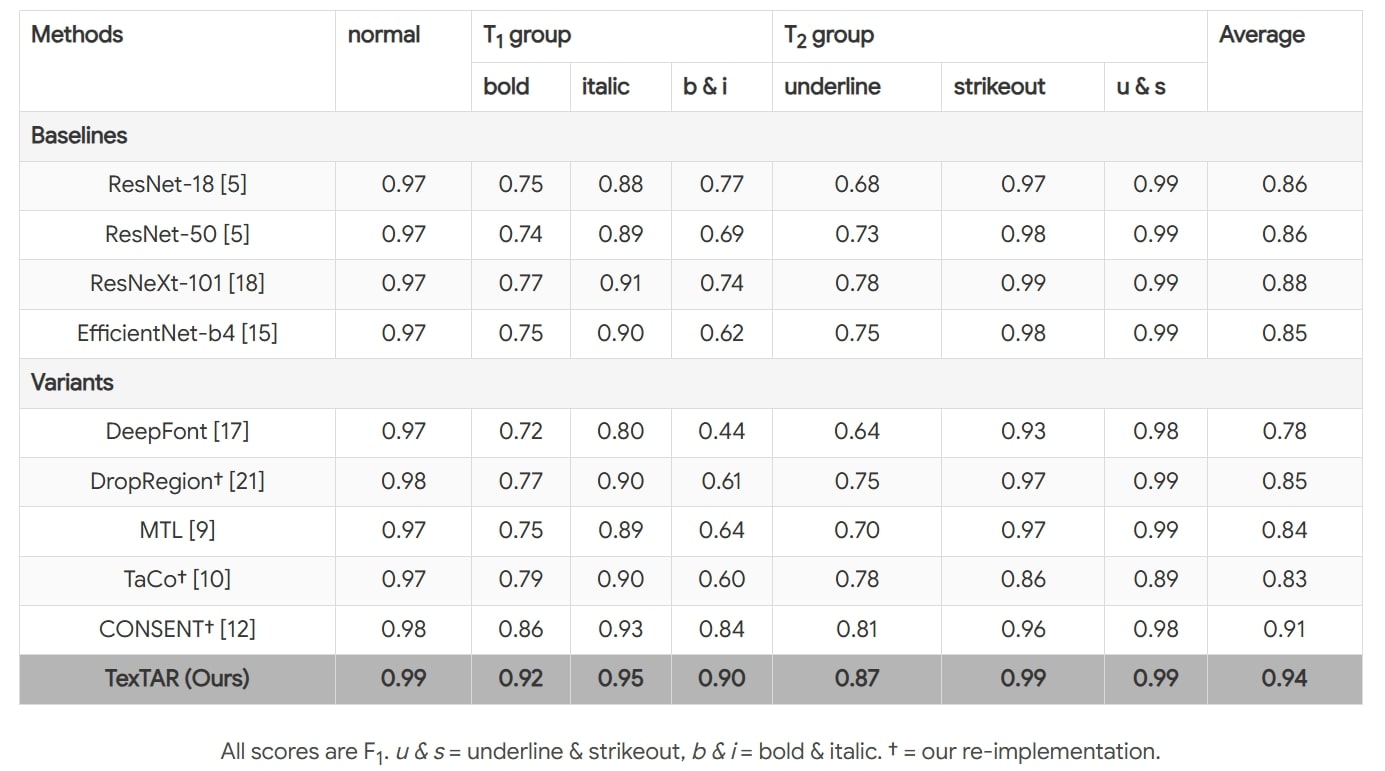
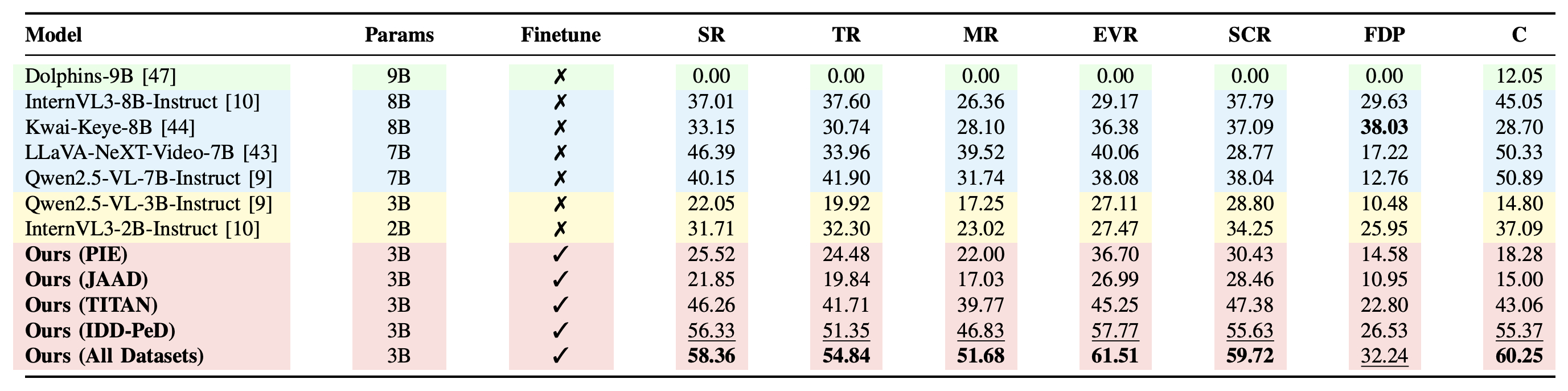
Results

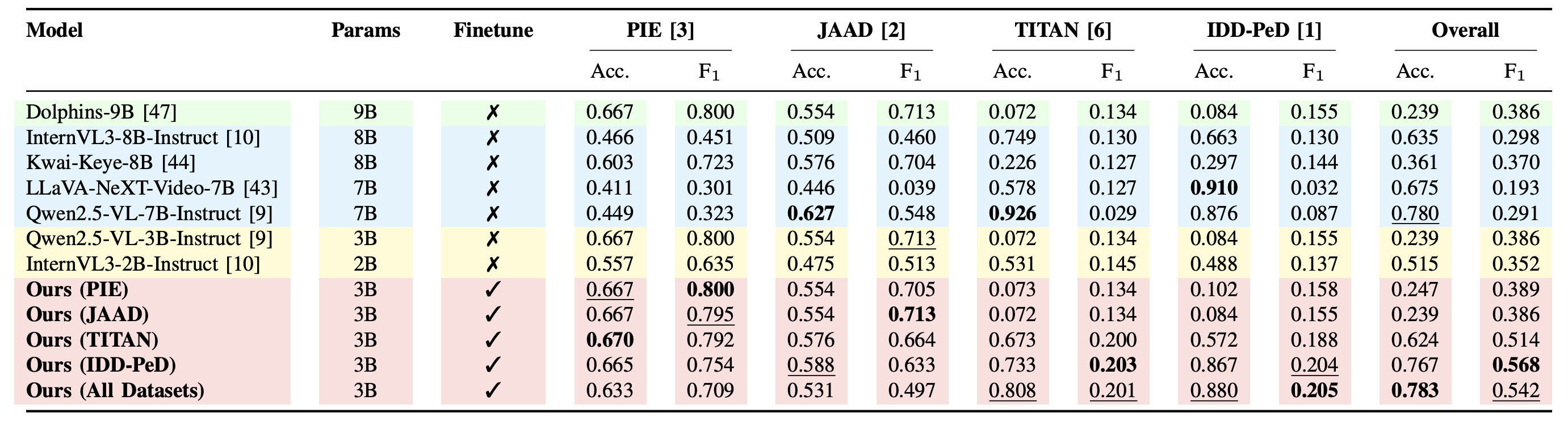
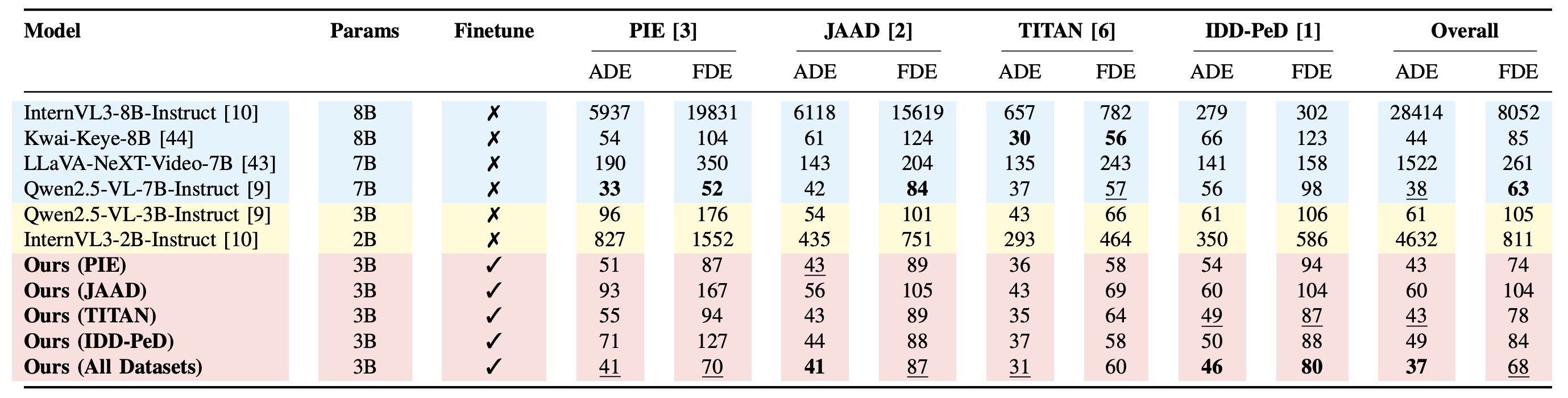
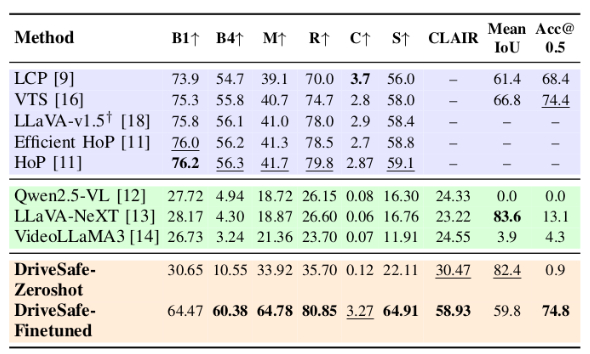
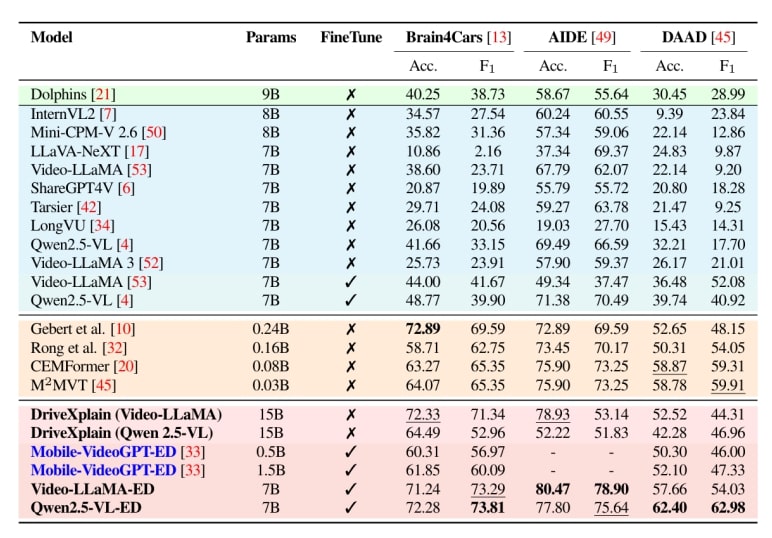
Table: Rationale evaluation on the combined dataset, with Claude-Sonnet-4. Average scores (0–100) for Spatial Reasoning (SR), Temporal Reasoning (TR), Mathematical Reasoning (MR), Ego-Vehicle Reasoning (EVR), Scene-Context Reasoning (SCR), Final Destination Prediction (FDP), and Conclusion (C). ✓ indicates finetuned models, ✗ zero-shot. Bold shows best score per column; underline marks the second-best. Dolphins generates only a brief conclusion and does not generate category-specific rationales.
Citation
@in proceedings{pedqa2026icra,
author = {Naman Mishra, Shankar Gangisetty, and C. V. Jawahar},
title = {PedestrainQA: A Benchmark for Vision-Language Models on
Pedestrian Intention and Trajectory Prediction},
booktitle = {},
series = {},
volume = {},
pages = {},
publisher = {},
year = {2026},
}
Acknowledgements
This work is supported by iHub-Data and Mobility at IIIT Hyderabad.