 Yashaswi Verma
Yashaswi Verma
Personal Home Page: http://researchweb.iiit.ac.in/~yashaswi.verma/
Publications
Journal Publications:
Ayushi Dutta, Yashaswi Verma, and and C.V. Jawahar - Automatic Image Annotation: The Quirks and What Works Multimedia Tools and Applications An International Journal (2018) [PDF]
Yashaswi Verma and C.V. Jawahar - A Support Vector Approach for Cross-modal Search of Images and Texts Computer Vision and Image Understanding 154 (2017): 48-63. [PDF]
Yashaswi Verma, C.V. Jawahar - Image Annotation by Propagating Labels from Semantic Neighbourhoods International Journal of Computer Vision (IJCV), 2016. [PDF]
Conference Publications:
Yashaswi Verma, C.V. Jawahar - A Robust Distance with Correlated Metric Learning for Multi-Instance Multi-Label Data Proceedings of the ACM Multimedia, 2016, Amsterdam, The Netherlands. [PDF]
Yashaswi Verma, C. V. Jawahar - A Probabilistic Approach for Image Retrieval Using Descriptive Textual Queries Proceedings of the ACM Multimedia, 26-30 Oct 2015, Brisbane, Australia. [PDF]
Yashaswi Verma, C.V. Jawahar - Exploring Locally Rigid Discriminative Patched for Learning Relative Attributes Proceedings of the 26th British Machine Vision Conference (BWVC), 07-10 Sep 2015, Swansea, UK. [PDF]
Yashaswi Verma and C.V. Jawahar - Im2Text and Text2Im: Associating Images and Texts for Cross-Modal Retrieval Proceedings of British Machine Vision Conference (BMVC), 01-05 Sep 2014, Nottingam, UK. [PDF]
Ramachandruni N. Sandeep, Yashaswi Verma and C.V. Jawahar - Relative Parts : Distinctive Parts of Learning Relative Attributes Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 23-28 June 2014, Columbus, Ohio, USA. [PDF]
Sandeep, Ramachandruni N, Yashaswi Verma and C.V. Jawahar - Relative parts: Distinctive parts for Learning Relative Attributes Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition(CVPR) 2014. [PDF]
Yashaswi Varma and C V Jawahar - Exploring SVM for Image Annotation in Presence of Confusing Labels Proceedings of the 24th British Machine Vision Conference (BMVC), 09-13 Sep. 2013, Bristol, UK. [PDF]
Yashaswi Verma, Ankush Gupta, Prashanth Mannem and C.V. Jawahar - Generating Image Descriptions using Semantic Similarities in the Output space Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops. 2013. [PDF]
Yashaswi Verma and C V Jawahar - Neti Neti: In Search of Deity Proceedings of the 8th Indian Conference on Vision, Graphics and Image Processing (ICVGIP), 16-19 Dec. 2012, Bombay, India. [PDF]
Yashaswi Varma and C V Jawahar - Image Annotation using Metric Learning in Semantic Neighbourhoods Proceedings of 12th European Conference on Computer Vision, 7-13 Oct. 2012, Print ISBN 978-3-642-33711--6, Vol. ECCV 2012, Part-III, LNCS 7574, pp. 114-128, Firenze, Italy. [PDF]
Ankush Gupta, Yashaswi Verma and C.V. Jawahar - Choosing Linguistics over Vision to Describe Images Conference on Artificial Intelligence (AAAI), 2012. [PDF]
Projects
 Learning relative attributes using parts
Learning relative attributes using parts
People Involved :Ramachandruni N Sandeep, Yashaswi Verma, C. V. Jawahar
Our aim is to learn relative attributes using local parts that are shared across categories. First, instead of using a global representation, we introduce a part-based representation combining a pair of images that specifically compares corresponding parts. Then, with each part we associate a locally adaptive “significance coefficient” that represents its discriminative ability with respect to a particular attribute. For each attribute, the significance-coefficients are learned simultaneously with a max-margin ranking model in an iterative manner. Compared to the baseline method , the new method is shown to achieve significant improvements in relative attribute prediction accuracy. Additionally, it is also shown to improve relative feedback based interactive image search.
 Image Annotation
Image AnnotationPeople Involved :Yashaswi Verma, C V Jawahar
In many real-life scenarios, an object can be categorized into multiple categories. E.g., a newspaper column can be tagged as "political", "election", "democracy"; an image may contain "tiger", "grass", "river"; and so on. These are instances of multi-label classification, which deals with the task of associating multiple labels with single data. Automatic image annotation is a multi-label classification problem that aims at associating a set of text with an image that describes its semantics.
 Praveen Krishnan
Praveen Krishnan
Publications
Conference Publication
Siddhant Bansal, Praveen Krishnan and C.V. Jawahar - Improving Word Recognition using Multiple Hypotheses and Deep Embeddings ,The 25th International Conference of Pattern Recognition (ICPR) (ICPR 2021), Milano [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Improving CNN-RNN Hybrid Networks for Handwriting Recognition, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Towards Spotting and Recognition of Handwritten Words in Indic Scripts, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew and C.V. Jawahar - Localizing and Recognizing Text in Lecture Videos, The 16th International Conference on Frontiers in Handwriting Recognition (ICFHR) 2018, Niagara Falls, USA [PDF]
Vijay Rowtula, Praveen Krishnan, C.V. Jawahar - POS Tagging and Named Entity Recognition on Handwritten Documents, ICON, 2018[PDF]
Praveen Krishnan, Kartik Dutta and C. V. Jawahar - Word Spotting and Recognition using Deep Embedding, Proceedings of the 13th IAPR International Workshop on Document Analysis Systems, 24-27 April 2018, Vienna, Austria. [PDF]
Kartik Dutta,Praveen Krishnan, Minesh Mathew and C. V. Jawahar - Offline Handwriting Recognition on Devanagari using a new Benchmark Dataset, Proceedings of the 13th IAPR International Workshop on Document Analysis Systems, 24-27 April 2018, Vienna, Austria. [PDF]
Kartik Dutta, Praveen Krishnan, Minesh Mathew, and C. V. Jawahar - Towards Accurate Handwritten Word Recognition for Hindi and Bangla National Conference on Computer Vision, Pattern Recognition, Image Processing and Graphics (NCVPRIPG), 2017 [PDF]
Praveen Krishnan and C.V Jawahar - Matching Handwritten Document Images, The 14th European Conference on Computer Vision (ECCV) – Amsterdam, The Netherlands, 2016. [PDF]
Praveen Krishnan, Kartik Dutta and C.V Jawahar - Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text, 15th International Conference on Frontiers in Handwriting Recognition, Shenzhen, China (ICFHR), 2016. [PDF]
Anshuman Majumdar, Praveen Krishnan and C.V. Jawahar - Visual Aesthetic Analysis for Handwritten Document Images,15th International Conference on Frontiers in Handwriting Recognition, Shenzhen, China (ICFHR), 2016. [PDF]
Praveen Krishnan, Naveen Sankaran, Ajeet Kumar Singh and C. V. Jawahar - Towards a Robust OCR System for Indic Scripts Proceedings of the 11th IAPR International Workshop on Document Analysis Systems, 7-10 April 2014, Tours-Loire Valley, France. [PDF]
Praveen Krishnan and C V Jawahar - Bringing Semantics in Word Image Retrieval Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), 25-28 Aug. 2013, Washington DC, USA. [PDF]
Praveen Krishnan, Ravi Sekhar, C V Jawahar - Content Level Access to Digital Library of India Pages Proceedings of the 8th Indian Conference on Vision, Graphics and Image Processing (ICVGIP), 16-19 Dec. 2012, Bombay, India. [PDF]
Journal Publication
Projects
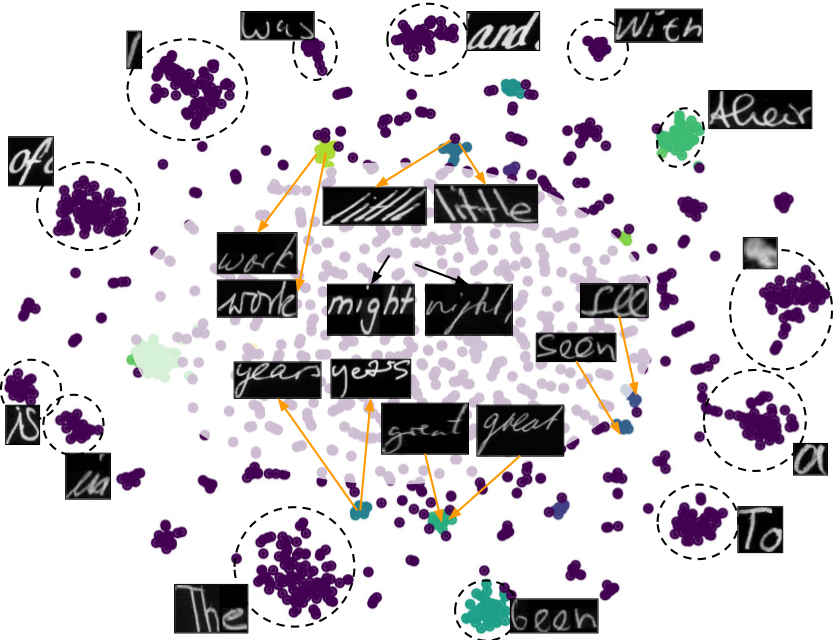
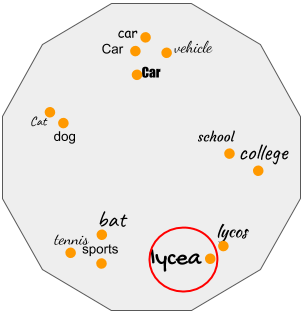 Bringing Semantics in Word Image Representation
Bringing Semantics in Word Image Representation
People Involved : Praveen Krishnan, C. V. Jawahar
In this work, we propose two novel forms of word image semantic representations. The first form learns an inflection invariant representation, thereby focusing on the root of the word, while the second form is built along the lines of textual word embedding techniques such as Word2Vec. We observe that such representations are useful for both traditional word spotting and also enrich the search results by accounting the semantic nature of the task.
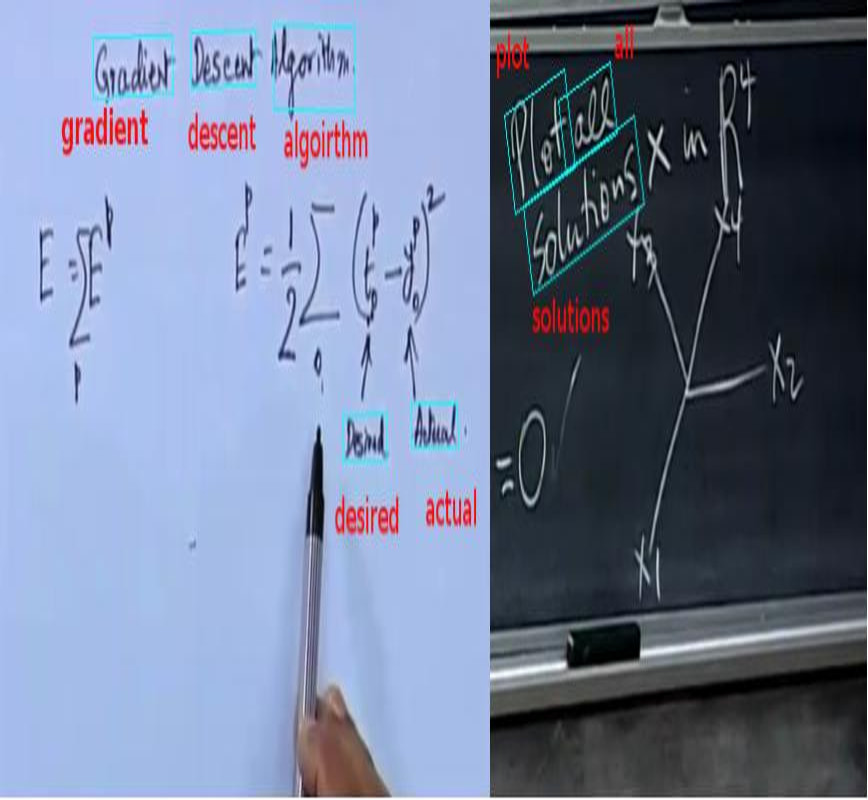 LectureVideoDB - A dataset for text detection and Recognition in Lecture Videos
LectureVideoDB - A dataset for text detection and Recognition in Lecture Videos
People Involved : Kartik Dutta, Minesh Mathew, Praveen Krishnan and CV Jawahar
Lecture videos are rich with textual information and to be able to understand the text is quite useful for larger video understanding/analysis applications. Though text recognition from images have been an active research area in computer vision, text in lecture videos has mostly been overlooked. In this work, we investigate the efficacy of state-of-the art handwritten and scene text recognition methods on text in lecture videos
 Word level Handwritten datasets for Indic scripts
Word level Handwritten datasets for Indic scripts
People Involved : Kartik Dutta, Praveen Krishnan, Minesh Mathew and CV Jawahar
Handwriting recognition (HWR) in Indic scripts is a challenging problem due to the inherent subtleties in the scripts, cursive nature of the handwriting and similar shape of the characters. Lack of publicly available handwriting datasets in Indic scripts has affected the development of handwritten word recognizers. In order to help resolve this problem, we release 2 handwritten word datasets: IIIT-HW-Dev, a Devanagari dataset and IIIT-HW-Telugu, a Telugu dataset.
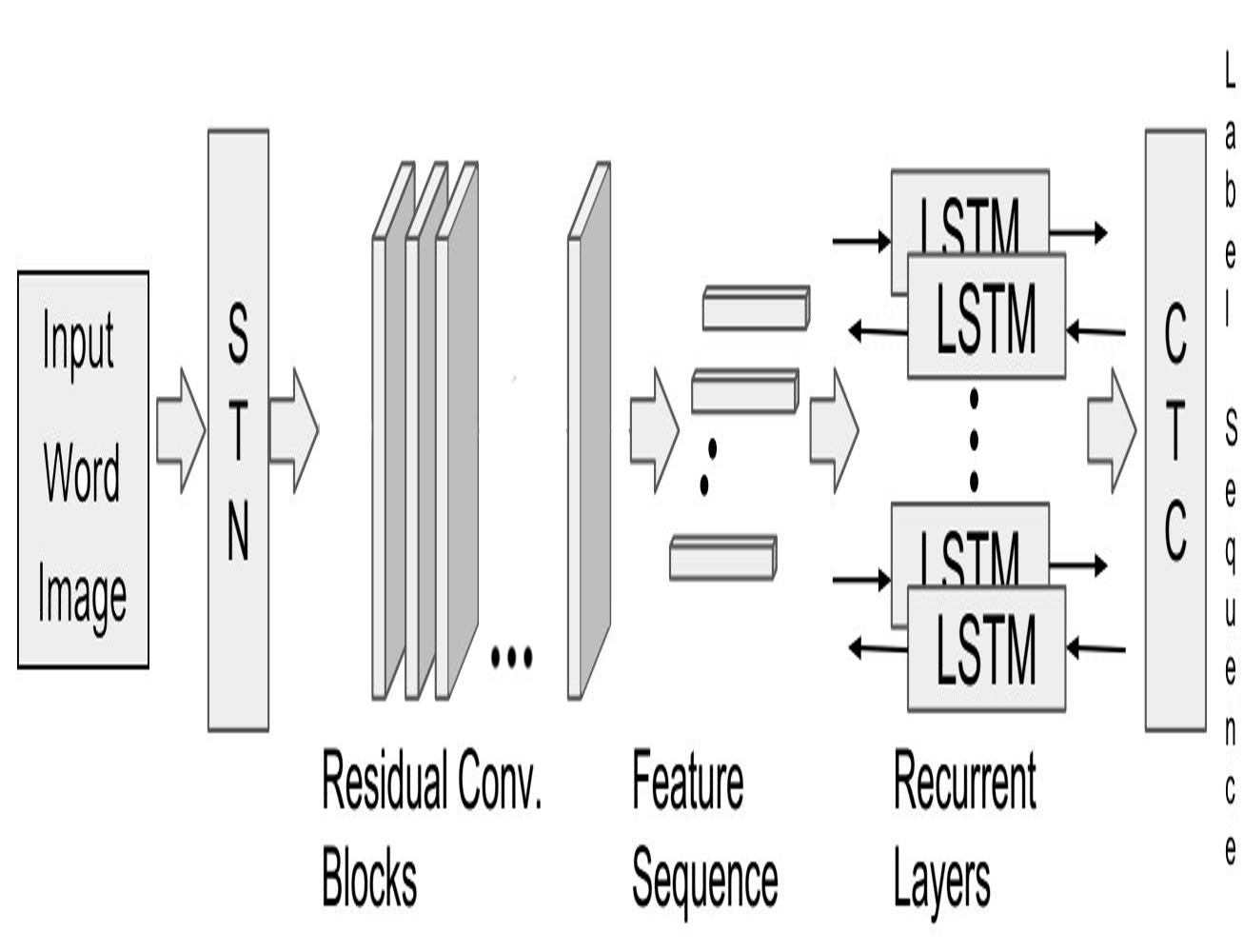
 HWNet - An Efficient Word Image Representation for Handwritten Documents
HWNet - An Efficient Word Image Representation for Handwritten Documents
People Involved : Praveen Krishnan, C. V. Jawahar
We propose a deep convolutional neural network named HWNet v2 (successor to our earlier work [1]) for the task of learning efficient word level representation for handwritten documents which can handle multiple writers and is robust to common forms of degradation and noise. We also show the generic nature of our representation and architecture which allows it to be used as off-the-shelf features for printed documents and building state of the art word spotting systems for various languages.
![]() Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text
Deep Feature Embedding for Accurate Recognition and Retrieval of Handwritten Text
People Involved : Praveen Krishnan, Kartik Dutta and C. V. Jawahar
We propose a deep convolutional feature representation that achieves superior performance for word spotting and recognition for handwritten images. We focus on :- (i) enhancing the discriminative ability of the convolutional features using a reduced feature representation that can scale to large datasets, and (ii) enabling query-by-string by learning a common subspace for image and text using the embedded attribute framework. We present our results on popular datasets such as the IAM corpus and historical document collections from the Bentham and George Washington pages.
![]() Matching Handwritten Document Images
Matching Handwritten Document Images
People Involved : Praveen Krishnan and C. V. Jawahar
We address the problem of predicting similarity between a pair of handwritten document images written by different individuals. This has applications related to matching and mining in image collections containing handwritten content. A similarity score is computed by detecting patterns of text re-usages between document images irrespective of the minor variations in word morphology, word ordering, layout and paraphrasing of the content.
 Visual Aesthetic Analysis for Handwritten Document Images
Visual Aesthetic Analysis for Handwritten Document Images
People Involved : Anshuman Majumdar, Praveen Krishnan and C. V. Jawahar
We present an approach for analyzing the visual aesthetic property of a handwritten document page which matches with human perception. We formulate the problem at two independent levels: (i) coarse level which deals with the overall layout, space usages between lines, words and margins, and (ii) fine level, which analyses the construction of each word and deals with the aesthetic properties of writing styles. We present our observations on multiple local and global features which can extract the aesthetic cues present in the handwritten documents.
 Parikshit Vishwas Sakurikar
Parikshit Vishwas Sakurikar
Publications
Parikshit Sakurikar, Ishit Mehta, Vineeth N Balasubramanian and P.J. Narayanan - RefocusGAN: Scene Refocusing using a Single Image European Conference on Computer Vision (ECCV), 2018, Munich, Germany [PDF]
Ishit Mehta, Parikshit Sakurikar and P.J. Narayanan - Structured Adversarial Training for Unsupervised Monocular Depth Estimation International Conference on 3D Vision (3DV), 2018, Verona, Italy [PDF]
Parikshit Sakurikar and P.J. Narayanan - Focal Stack Representation and Focus Manipulation 4th Asian Conference on Pattern Recognition (ACPR), 2017, Nanjing, China. [PDF]
Saurabh Saini, Parikshit Sakurikar and P. J. Narayanan - Intrinsic Image Decomposition using Focal Stacks, Proceedings of the Tenth Indian Conference on Computer Vision, Graphics and Image Processing. ACM, 2016. [PDF]
Parikshit Sakurikar and P. J. Narayanan - Dense View Interpolation on Mobile Devices Using Focal Stacks Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR-W), 2014. [PDF]
Pawan Harish, Parikshit Sakurikar, P J Narayanan - Increasing Instensity Resolution on a Single Display using Spatio-Temporal Mixing Proceedings of the 8th Indian Conference on Vision, Graphics and Image Processing (ICVGIP), 16-19 Dec. 2012, Bombay, India. [PDF]
Parikshit Sakurikar and P J Narayanan - Fast Graph Cuts using Shrink-Expand Reparameterization Proceedings of IEEE Workshop on Applications of Computer Vision (WACV) 9-11 Jan. 2012, ISSN 1550-5790 E-ISBN 978-1-4673-0232-6, Print ISBN 978-1-4673-0233-3, pp. 65-71, Breckenridge, CO, USA. [PDF]
Projects
 Computational Displays
Computational DisplaysPeople Involved :Parikshit Sakurikar, Revanth N R, Pawan Harish, Nirnimesh and P J Narayanan
Displays have seen many improvements over the years but have many shortcomings still. These include rectangular shape, low color gamut, low dynamic range, lack of focus and context in a scene, lack of 3D viewing, etc. We propose Computational Displays, which employ computation to economically alleviate some of the shortcomings of today's displays.
 Parallel Computing using CPU and GPU
Parallel Computing using CPU and GPU
People Involved : Aditya Deshpande, Parikshit Sakurikar, Harshit Sureka, K. Wasif, Ishan Misra, Pawan Harish, Vibhav Vineet and P J Narayanan
Commodity graphics hardware has become a cost-effective parallel platform for solving many general problems. New Graphics hardware by Nvidia offers an alternate programming model called CUDA which can be used in more flexible ways than GPGPU.
 Anand Mishra
Anand Mishra
Publications
Journal Publication:
Anand Mishra, Karteek Alahari and C.V. Jawahar - Unsupervised Refinement of Color and Stroke Features for Text Binarization International Journal on Document Analysis and Recognition (IJDAR) (2017): 1-17. [PDF]
Anand Mishra, Karteek Alahari and C. V. Jawahar - Enhancing Energy Minimization Framework for Scene Text Recognition with Top-Down Cues - Computer Vision and Image Understanding (CVIU 2016), volume 145, pages 30–42, 2016. [PDF]
Conference Publication:
Suyash Maniyar, Vishvesh Trivedi, Ajoy Mondal, Anand Mishra, and C V Jawahar - AI - Generated Lecture Slides for Improving Slide Element Detection and Retrieval, In International Conference on Document Analysis and Recognition (ICDAR), 2025 [ PDF ]
Ashutosh Mishra, Shyam Nandan Rai, Anand Mishra and C. V. Jawahar, IIIT-CFW: A Benchmark Database of Cartoon Faces in the Wild, 1st workshop on visual analysis and sketch (ECCVW) 2016. [PDF]
Ajeet Kumar Singh, Anand Mishra, Pranav Dabral and C V Jawahar - A Simple and Effective Solution for Script Identification in the Wild - Proceedings of 12th IAPR International Workshop on Document Analysis Systems (DAS'16), 11-14 April, 2016, Santorini, Greece. [PDF]
Sirnam Swetha, Anand Mishra, Guruprasad M. Hegde and C. V. Jawahar - Efficient Object Annotation for Surveillance and Automotive Applications - Proceedings of the IEEE Winter Conference on Applications of Computer Vision Workshop (WACVW 2016), March 7-9, 2016. [PDF]
Udit Roy, Anand Mishra, Karteek Alahari, C.V. Jawahar - Scene Text Recognition and Retrieval for Large Lexicons Proceedings of the 12th Asian Conference on Computer Vision,01-05 Nov 2014, Singapore. [PDF] [Abstract] [Poster] [Lexicons] [bibtex]
Anand Mishra, Karteek Alahari and C V Jawahar - Image Retrieval using Textual Cues Proceedings of International Conference on Computer Vision (ICCV), 1-8th Dec.2013, Sydney, Australia. [Pdf] [Abstract] [Project page][bibtex]
Vijay Kumar, Amit Bansal, Goutam Hari Tulsiyan, Anand Mishra, Anoop M. Namboodiri, C V Jawahar - Sparse Document Image Coding for Restoration Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), 25-28 Aug. 2013, Washington DC, USA. [PDF]
Vibhor Goel, Anand Mishra, Karteek Alahari, C V Jawahar - Whole is Greater than Sum of Parts: Recognizing Scene Text Words Proceedings of the 12th International Conference on Document Analysis and Recognition (ICDAR), 25-28 Aug. 2013, Washington DC, USA. [PDF] [Abstract] [bibtex]
Deepan Gupta, Vaidehi Chhajer, Anand Mishra, C V Jawahar - A Non-local MRF model for Heritage Architectural Image Completion Proceedings of the 8th Indian Conference on Vision, Graphics and Image Processing (ICVGIP), 16-19 Dec. 2012, Bombay, India. [PDF]
Anand Mishra, Karteek Alahari and C V Jawahar - Scene Text Recognition using Higher Order Language Priors Proceedings of British Machine Vision Conference (BMVC), 3-7 Sep. 2012, Guildford, UK. [PDF] [Abstract] [Slides] [bibtex]
Anand Mishra, Karteek Alahari and C V Jawahar - Top-down and Bottom-up Cues for Scene Text Recognition Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), 16-21 June 2012, pp. 2287-2294, Providence RI, USA. [PDF] [Abstract] [Poster] [bibtex]
Anand Mishra, Naveen Sankaran, Viresh Ranjan and C.V. Jawahar - Automatic Localization and Correction of Line Segmentation Errors Proceeding of the workshop on Document Analysis and Recognition (DAR), 2012. [PDF]
Dheeraj Mundhra, Anand Mishra and C.V. Jawahar - Automatic Localization of Page Segmentation Errors Proceedings of Joint Workshop on Multilingual OCR and Analytics for Noisy Unstructured Text Data (J-MOCR-AND),17 September, 2011, Beijing, China. [PDF]
Anand Mishra, Karteek Alahari and C.V. Jawahar - An MRF Model for Binarization of Natural Scene Text Proceedings of 11th International Conference on Document Analysis and Recognition (ICDAR 2011),18-21 September, 2011, Beijing, China. [PDF] [Abstract] [Slides] [bibtex]
Projects
 The IIIT-CFW dataset
The IIIT-CFW datasetPeople Involved : Ashutosh Mishra, Shyam Nandan Rai, Anand Mishra, C. V. Jawahar
The IIIT-CFW is database for the cartoon faces in the wild. It is harvested from Google image search. Query words such as Obama + cartoon, Modi + cartoon, and so on were used to collect cartoon images of 100 public figures. The dataset contains 8928 annotated cartoon faces of famous personalities of the world with varying profession. Additionally, we also provide 1000 real faces of the public figure to study cross modal retrieval tasks, such as, Photo2Cartoon retrieval. The IIIT-CFW can be used for the study spectrum of problems as discussed in our ECCVW paper.
 Scene Text Understanding
Scene Text UnderstandingPeople Involved :Udit Roy, Anand Mishra, Karteek Alahari and C.V. Jawahar
Scene text recognition has gained significant attention from the computer vision community in recent years. Often images contain text which gives rich and useful information about their content. Recognizing such text is a challenging problem, even more so than the recognition of scanned documents. Scene text exhibits a large variability in appearances, and can prove to be challenging even for the state-of-the-art OCR methods. Many scene understanding methods recognize objects and regions like roads, trees, sky etc in the image successfully, but tend to ignore the text on the sign board. Our goal is to fill this gap in understanding the scene.
 Arunava Chakravarty
Arunava Chakravarty
Publications
Chakravraty A, Gaddipati DJ and Jayanthi Sivaswamy - Construction of a Retinal Atlas for Macular OCT Volumes ICIAR 2018, Portugal [PDF]
Chakravarty and Jayanthi Sivaswamy - End-to-End Learning of a Conditional Random Field for Intra-retinal Layer Segmentation in Optical Coherence Tomography Annual Conference on Medical Image Understanding and Analysis. Springer, Cham, 2017. [PDF]
Arunava Chakravarty and Jayanthi Sivaswamy - Glaucoma Classification with a Fusion of Segmentation and Image-based Features Proc. of IEEE International Symposium on Bio-Medical Imaging(ISBI), 2016, 13 - 16 April, 2016, Prague. [PDF]
Ujjwal, Arunava Chakravarty, Jayanthi Sivaswamy - An Assistive Annotation System for Retinal Images Proceedings of the IEEE International Symposium on Biomedical Imaging : From Nano to Macro, 16-19 April 2015.[PDF]
Arunava Chakravarthy, Jayanthi Sivaswamy - Coupled Sparse Dictionary for Depth-based Cup Segmentation from Single Color Fundus Image Proceedings of the MICCAI 2014, 14-18 Sep 2014, Boston,USA. [PDF]
M J J P Van Grinsven, Arunava Chakravarty, Jayathi Sivaswamy, T. Theelen, B. Van Ginneken, C I Sanchez - A Bag of Words Approach for Discriminating between Retinal Images Containing Exudates or Drusen Proceedings of the IEEE 10th International Symposium on Biomedical Imaging : From Nano to Macro (ISBI), 07-11 April. 2013, San Franciso,CA,USA. [PDF]
Ujjwal, K. Sai Deepak, Arunava Chakravarty, Jayathi Sivaswamy - Visual Saliency based Bright Lesion Detection and Discrimination in Retinal Images Proceedings of the IEEE 10th International Symposium on Biomedical Imaging : From Nano to Macro (ISBI), 07-11 April. 2013, San Franciso,CA,USA. [PDF]
Arunava Chakravarty, Jayanthi Sivaswamy - A Novel Approach for Quantification of Retinal Vessel Tortuosity using Quadratic Polynomial Decomposition Proceedings of the indian Conference on Medical Informatics and Telemedicine, 28-30 Mar. 2013, Kharagpur, INDIA.. [PDF]
Projects
People Involved : Gopal Datt Joshi, Mayank Chawla, Arunava Chakravarty, Akhilesh Bontala, Shashank Mujjumdar, Rohit Gautam, Subbu, Sushma
Digital medical images are widely used for diagnostic purposes. Our goal is to develop algorithms for medical image analysis focusing on enhancement, segmentation, multi-modal registration and classification.
 Retinal Image Analysis
Retinal Image AnalysisPeople Involved : Arunava, Ujjwal, Gopal, Akhilesh, Sai, Yogesh
Analysis of retinal images for diagnostic purposes